Notes on ICML 2021 about Federated Learning
ㅤ
Gaoxiang: There are plenty of Federated Learning papers in ICML 2021, so I plan to categorize them depending on their main contribution, and particularly study the development of Federated Learning training algorithms. Images of this blog are from the corresponding invited talks of ICML 2021.
Optimization
Basic Training Objective
We want to minimize this object function efficiently in terms of:
- Computation (stochastic gradients, mini-batches)
- Communication (server, clients)
Base-Algorithm: SGD
What we do here is just to pick a data sample or a mini-batch, compute the gradient, and move toward the negative direction of this gradient. In practice, you can also use SGD with momentum, ADAM, AdaGrad, etc, but in this blog we will stay with SGD because it’s the simplest and most common.
SGD convergence
Here we only illustrate the case where there is only one client.
(Standard) Assumptions
- bounded noise:
- L-smoothness:
Convergence of SGD
- L-smooth convergence, criterion:
, gradient computations
-star convex, criterion:
, gradient computations
By the way, is not the last iterate (typically a random iterate). In the following discussion, we will assume
-star convexity, which is a slightly weaker form than strong convexity.
FYI, -star convex is
s.t.
.
Mini-batch SGD baseline
Ask every client to send the stochatic gradient and compute the whole gradient of every clients. This is a unbiased estimator.
where we assume the perfectly tuned stepsize.
Convergence of mini-batch SGD
- rounds needed to converge:
, where
is the number of clients, and this is also called linear speedup. Additionally,
is the batch size.
- total gradients needed to converge:
Problem of mini-batch SGD:
- We have to send the model to every client. The client computes one SGD and send it back. This is very communicational heavy algorithms, especially the model can be 1G or even larger in size.
- Because communication is expensive, we might think of just compute a larger batch each time. Although increasing batch size
, stuck at
forever. In other words, if there is more data of each batch, the data distribution is likely to have larger variance. Then taking the average of the summation of the gradient might end up having a small magnitude.
- Can we find a algorithm that comptues same amount of gradients or less, and converge in less rounds than mini-batch SGD? It turns out that mini-batch SGD is a very hard baseline to beat…
Local-SGD
If communication is the bottleneck, then why don’t we compute the gradients as much as we can on local client?
where in general for
and
Pros:
- leverages parallelism (unlike single client SGD)
- make
- performs good in experiements
Analysis of Local SGD
The main idea is to study the virtual average:
where bahaves almost as normal SGD because of
. Also, the additional error term
, the difference between the client model and the average model, can be controlled.
- For IID data:
- For non-IID data:
where
. The additional parameter
is used to measure how different these data distrubutions are, which is called data-dissimilarity to measure the inter-client variance.
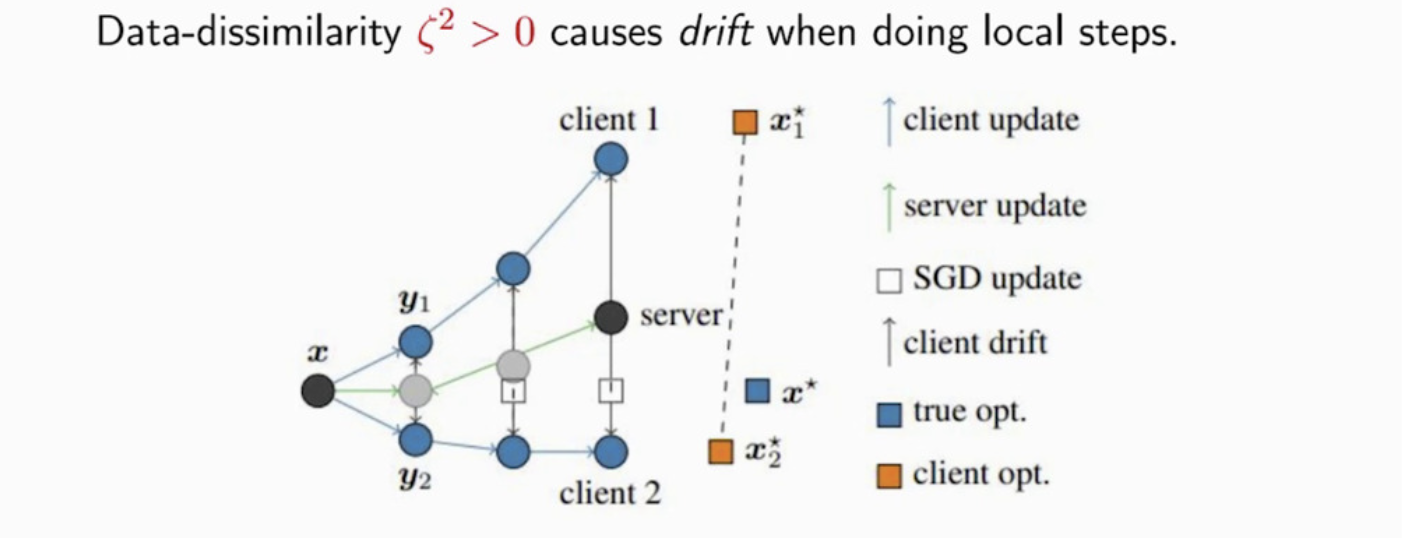
In the literature, data-dissimilarity causes client drift. The client model starts to overfit their local data, and hence maybe very far away from the global optimal solution.
Convergence Round
- Mini-batch SGD:
- Local SGD:
On the positive side, we see that the Local SGD congerges! On the negative side, we see that Local SGD has one more term than the mini-batch SGD, and a recent work shows Local SGD cannot be significantly improved, but in practices Local SGD is much better than mini-batch SGD in many functions in federarted learning.
SCAFFOLD and Mime
To address the local drift issue that is very common in federated learning training algorithms, one of the apporaches we can try is to correct the bias in local update. The basic idea is as the following:
There is a drift of each client, and each client likes to move toward its own negative local gradient direction. Here we like the global model move toward the gradient of the whole gradient (i.e., the big function), so what we can do is to substract the local drift and add the global drift direction. We just need to be careful in a way that the drift correction doesn’t depend on the local update and is unbiased.
Implementation Sketch
- SCAFFOLD: if
is small, SVRG/SAGA-type correction
- Mime: if
where denotes a (stochastic (possibly mini-batch) or full batch) gradient.
Additionally, SCAFFOLD’s theoretical result is quite close to mini-batch SGD in terms of convergence rounds.
- Mini-batch SGD:
- SCAFFOLD:
Yes, all these work have been done is just to get an approximate convergence round as mini-batch SGD. That’s why I said earlier that mini-batch SGD is a difficult baseline to beat. Let’s look at some experiments results of SCAFFOLD:

As you can see from the image above, for non-IID data we see the SCAFFLOD with drift correction reaches much less rounds to converge than SGD and FedAvg. On the other hand, we see that in IID data there isn’t really a need to do drift correction, so the performance of SCAFFOLD and FEFAVG is quite similiar, which is what we expected. But do we really have no other benefits of doing local updates?
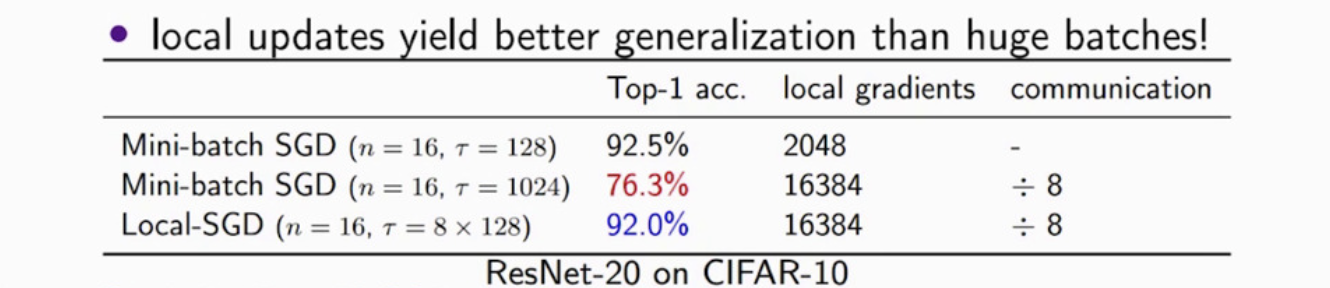
Absolutely not! As you see from the image above, sometimes the local steps can have a better generalization than using a large-batch SGD. The second row is the result of using a large-batch in mini-batch SGD. Compared to the third row of Local-SGD, they have the same amount of computation locally but Local-SGD yields better generalization.
Reference
- Communication-Efficient Learning of Deep Networks from Decentralized Data [arXiv]
- Advances and Open Problems in Federated Learning [arXiv]
- Mime: Mimicking Centralized Stochastic Algorithms in Federated Learning [arXiv]
- Minibatch vs Local SGD for Heterogeneous Distributed Learning [arXiv]
- Is Local SGD Better than Minibatch SGD? [arXiv]
- A Unified Theory of Decentralized SGD with Changing Topology and Local Updates [arXiv]
- Accelerating Stochastic Gradient Descent using Predictive Variance Reduction (SVRG) [NIPS]
- SAGA: A Fast Incremental Gradient Method With Support for Non-Strongly Convex Composite Objectives [arXiv]
- Less than a Single Pass: Stochastically Controlled Stochastic Gradient Method (SCSG) [arXiv]
- SCAFFOLD: Stochastic Controlled Averaging for Federated Learning [arXiv]
BVR-L-SGD (ICML 2021) [arXiv]
Similiar to SCAFFOLD, BVR-L-SGD also deals with the bias caused by localization by subtracting the local gradient and adding the global whole gradient, but it takes two steps further: firstly, it applies stochastization to reduce computation and further reduce the variance caused by stochastization. This work aims to improve the communication complexity as the following comprarision:
- (Minibatch SGD):
- (Local SGD):
- (BVR-L-SGD):
The following is some numerical results on CIFAR10 dataset:
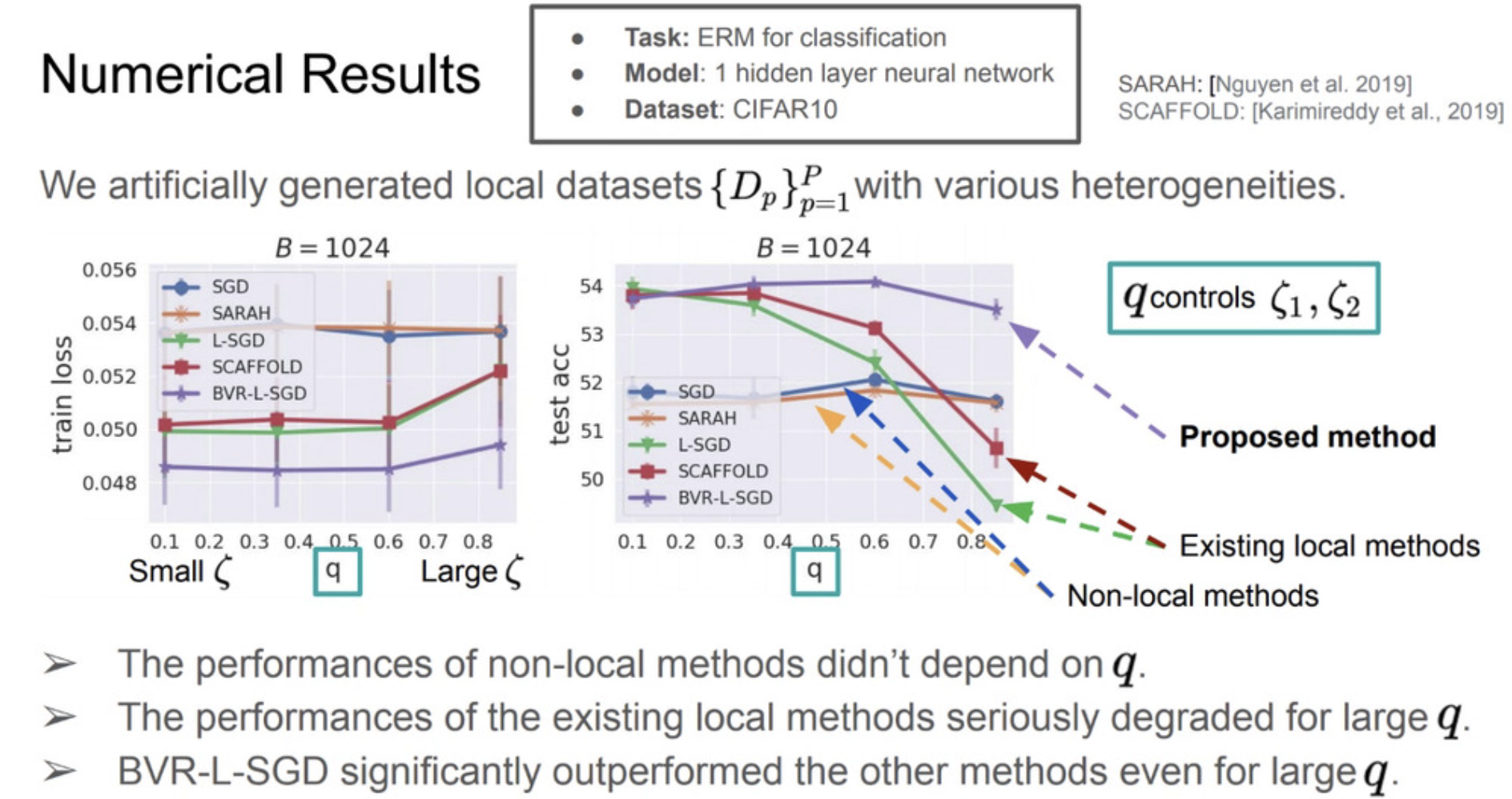
Limitation: these results were only based on a shallow neural network (1-hidden-layer neural network).
AsyncCommSGD (ICML 2021) [ICML]
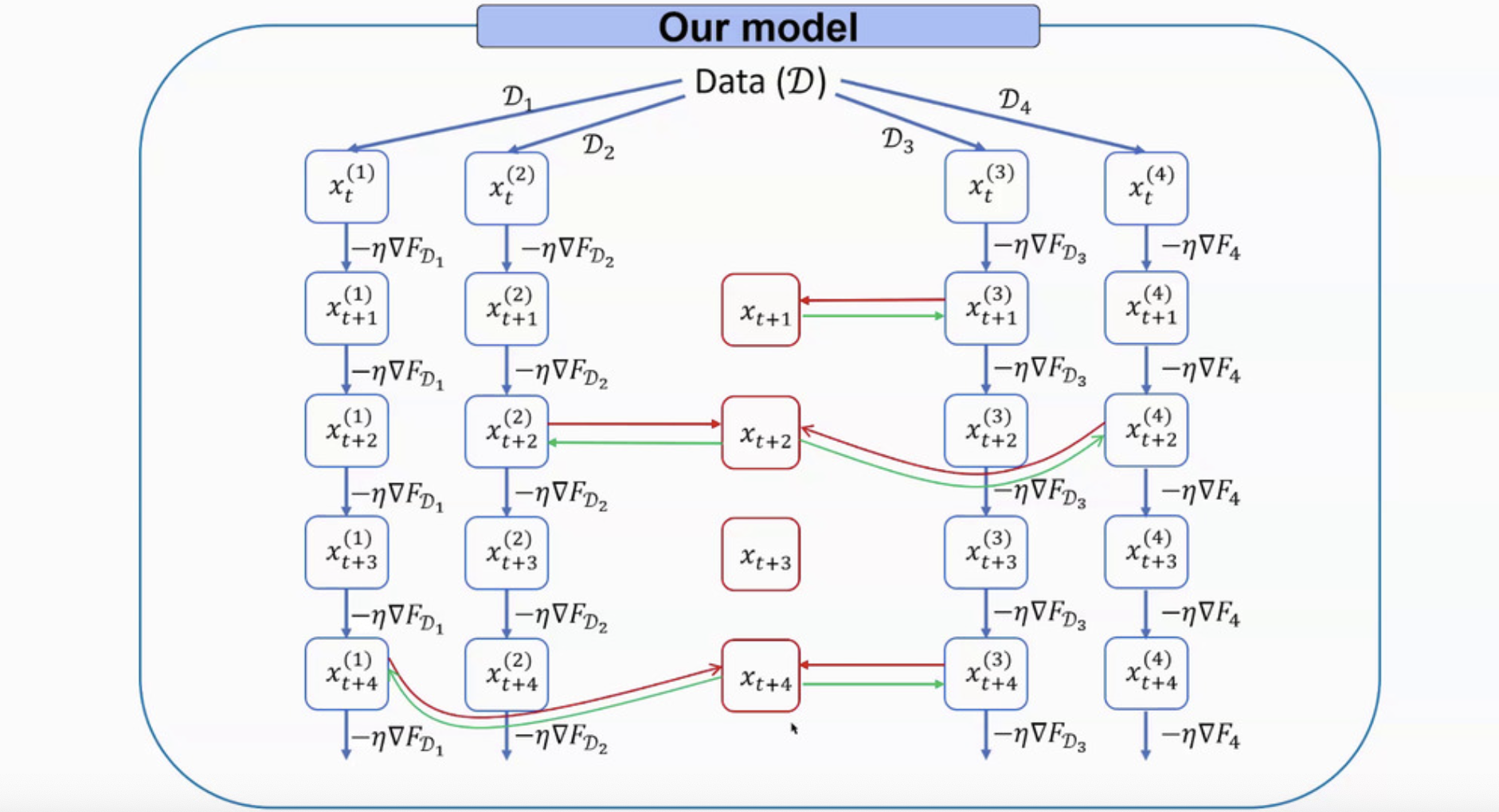
While Local-SGD and FedAvg are interchangeable sometimes, there is still a difference as the following image shown.
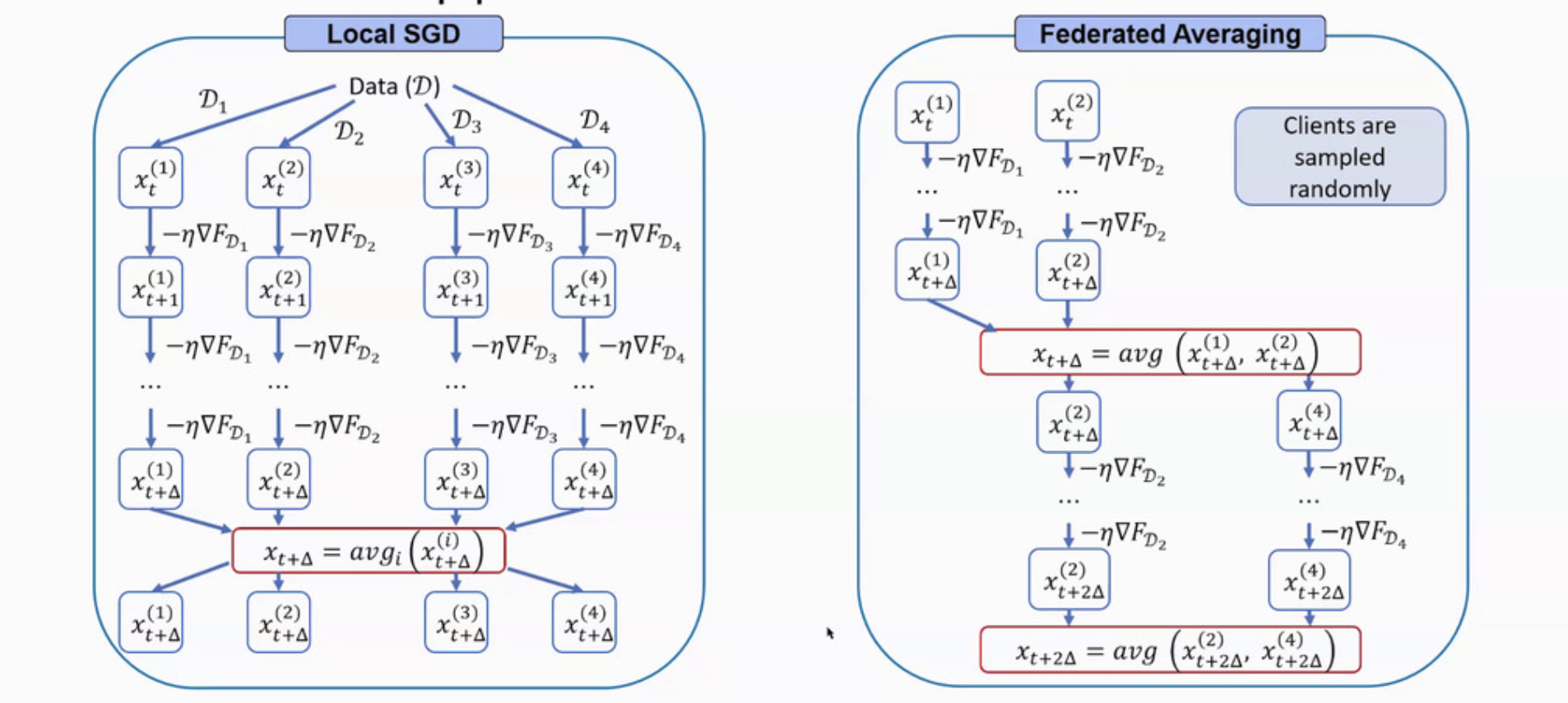
There are problems with these two existing apporaches. Local SGD waits for each client to communicate. Additionally, in practice FedAvg often selects first respondin clients, introducing bias.
Hence, the AsyncCommSGD was proposed to reduce the communication cost. Each client still computes at every iteration, but at every iteration, only some clients may communicate with the server. But different from some arbitrary-communication papers, AsyncCommSGD includes a so-called communication gap that ensures each client communicates within iterations. The mechanism is as the following image:
CODA+/CODASCA [arXiv]
The author proposed CODA+ based on a federated learning algorithm CODA+ based on AUC maximization. However, CODA+ still suffers from a high communication complexity for hetergeneous (i.e., non-IID) data. Hence, they adopted the idea of SCAFFOLD to correct client drift and proposed CODASCA. They also showed CODASCA performs better than CODA+ in real-world dataset including CheXpert, but the improvement was minimal. Also, the data source only came from CheXpert and some imbalanced-and-heterogeneous preprocessing were performed to set up the federated learning situation.
Hardware Constrains
How to make use of the limited available resource and minimize the training time?
- Number of local updates between two global aggregations
- Adaptive federated learning in resource constrained edge computing systems [arXiv])
- Model sparsification
- Adaptive gradient sparsification for efficient federated learning: an online learning approach [arXiv]
- Model pruning
- Model pruning enables efficient federated learning on edge devices [arXiv]
Personalization for Robustness
What is personalized FL?
Personalized FL allows each party to solve its own model and use the federation to get a boost from other parties.
Why is personalized FL?
It offers the flexibility needed by industrial applications to optimzie modles for their own settings, while benefitting optimally from each from the federation.
- Fed+ provides a robust and mean aggregation, which is provably congergent and easy to implement.
- Fed+ for robustness and personalization [arXiv]
- Ditto addresses the fairness and robustness in federation learning through personalization. It claims to address the constraint of fairness is to represent disparity in data; to address robustness is to against data and model poisoning attacks. And Personalization can achieve robustness and fairness simultaneously.
The formulation of Ditto:
for each device . Each client solves a local objective through a personalized model for
, where they constrains
to be close to
. And
is the optimal model by solving the global objective
, where
can be any aggregate function over client
to client
. For instance,
can be FedAvg then it’s to learn the weighted average across all clients. When
, Ditto is reduced to learn seperate models for each client. When
, Ditto is recovering learning a single global model
.
- Ditto: Fair and Robust Federated Learning Through Personalization [arXiv]
Privacy Perserving
Model update used in FL is not private. A large portion of training data can be reconstructed by just looking at the gradients. Representative works includes:
- DLG: Deep Leakage from Gradients [arXiv]
- iDLG: Improved Deep Leakage from Gradients [arXiv]
- IG: Inverting Gradients [arXiv]
To have a efficient and privacy-preserving training in FL, there are some related papers working on it from this conference: