Last day of class: the end? the beginning!
ㅤ
Today is the last day of class at the U, and it’s also the end of my undergraduate journey. I was touched by a a blog Optimize Your Life with Stochastic Gradient Descent (Mu, 2021), and I’d like to jot down something to summarize my feeling about being an undergrad CS researcher.
Looking back, the path of CS research is always non-linear, but at least we should more or less have an objective.
This objective doesn’t have to be non-convex; sometimes, you don’t even know the global optimal. However, you can start with an attainable objective, such as taking an introduction to machine learning class (if not offered, there are excellent resources on Couresa), and then training a linear model to accumulate your knowledge on CS research. I spent quite some time narrowing my research interests to some particular fields. If your objective is too general, the learning rewards tend to be sparse (Hare, 2021). In contrast, those objectives that converge well are usually small and specific such as image classification tasks.
No matter how complex your objective is, stochastic gradient descent is always the simplest.
Find a direction that you think it’s the most promising at the moment, and take a step. If interesting, take several more steps. These steps are like your knowledge of the realm of computing research. If there aren’t many changes, you may get stuck in your comfort zone (saddle point, or local optimal, maybe). In the early stage, I hope you appreciate this optimizer’s “stochastic” attribute. The realm of computing research is enormous; it doesn’t hurt to explore different research areas stochastically. However, once you find your niche, you should add some regularizations. As far as we know, adding penalty terms is an oldie-but-goodie trick to get a reasonable converge rate and good generalization.
Learn to use a scheduler with your optimizer.
I often found some periods extremely stressful throughout my college years, wildly when exams and deadlines were crashing together. This scenario is just like gradient explode. Use a scheduler to give yourself a break during stressful times, especially for undergraduates whose primary responsibilities aren’t conducting only research. And there are phenomena like “double descent” (Nakkiran, 2019), so don’t worry about spending the necessary time to rest, and remember to plan ahead accordingly.
Don’t take initialization personally. You’re who you are.
You may think there are people born with large-scale inherited pre-trained weights, and their initialization may be already closer to the optimal. They could even use zero-shot methods. As a first-generation college student, I usually don’t have the resources to tackle the challenges that my peers could navigate easily. Yet, a well-known paper by Facebook AI Research (FAIR) (Kaiming, 2019) uses massive experiments to show that random initialization can also match pre-training. You’re an overparameterized algorithm with more potential than you know. Recent theoretical work (“lazy training”) (Chizat, 2019) has shown that your parameters hardly vary from the initialization, usually bounded within a Euclidean ball with a certain radius. So, don’t be discouraged that people may have more resources than you. Be yourselves, and seize the opportunities that the computing society has provided for underrepresented groups. Help your peers! That’s what we do in transfer learning!
Failure is as important as success, as well as when to quit.
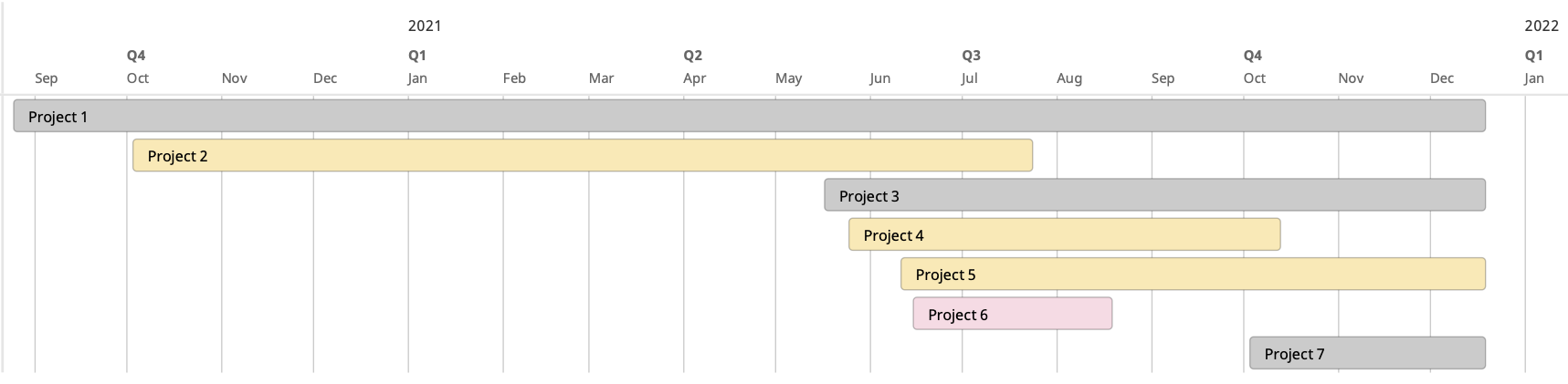
Figure 1: My undergraduate research projects: red for failed research, yellow for at least pre-prints, grey for on-going research.
There is nothing wrong with failing, and perhaps we should even expect failure to be part of the journey. I more or less participated in 7 research projects during my undergrad, but not all of them could eventually lead to positive outcomes (see Figure 1). During summer, I spent two months working on a research project (No.6 in Figure 1) and realized it wouldn’t work, primarily because I hadn’t checked with my advisor frequently. It’s ok to let go of a project; otherwise, what you get in the end will still be Nah with already wasted computes. Just like checking your gradients throughout epochs during training, check with or even “push” your advisor frequently. And it’s not a shame to give up a long-going research project. It’s about timing. My undergrad research advisor used to say working on theoretical machine learning is a high risk but not necessarily a high reward. It’s vital to know when to jump into theories; and, more importantly, when to jump out.
Undergraduate is not an end, but a beginning.
Best regards.
Reference
[1] Mu Li. 用随机梯度下降来优化人生. Zhihu. Sep, 2021. https://zhuanlan.zhihu.com/p/414009313
[2] Joshua Hare. Dealing with sparse rewards in reinforcement learning. arXiv. https://arxiv.org/abs/1910.09281
[3] Kaiming He, Ross Girshick, and Piotr Dollár. Rethinking imagenet pre-training. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[4] Preetum Nakkiran, et al. Deep Double Descent: Where Bigger Models and More Data Hurt. arXiv. https://arxiv.org/abs/1912.02292
[5] Lenaic Chizat, Edouard Oyallon, and Francis Bach. On lazy training in differentiable programming. arXiv. https://arxiv.org/abs/1812.07956