Large language models (LLMs) are increasingly deployed as decision making components in real-world systems for societal and scientific applications, creating a growing need for reliable predictions. In this paper, we study the problem of reliable decision making with LLMs via the lens of selective prediction, allowing the model to improve performance by trading-off coverage. The aim of selective prediction is to balance the key tradeoff of risk and coverage, where risk measures the predictive performance on selected inputs and coverage measures the fraction of abstentions. While existing LLM post-training approaches focus primarily on correctness or calibration, we propose to directly optimize for selective prediction performance by introducing reinforcement Learning for Selection Reward (RLSR), which targets the area under the risk-coverage curve (AURC) as its training objective. RLSR achieves substantially better risk-coverage tradeoff compared to multiple baselines on both in-domain and out-of-domain tasks.
@inproceedings{luo2026aligning,title={Aligning Language Models with Selective Prediction},author={Luo, Gaoxiang and Wu, Yifan and Zhang, Sinian and Deshwal, Aryan and Sun, Ju},booktitle={Forty-third International Conference on Machine Learning Second Workshop on Agents in the Wild: Safety, Security, and Beyond},year={2026},url={https://openreview.net/forum?id=bqTLnXswlC},}
Recently, vision foundation models have been shown to boost the efficiency of flow-based generative models by revealing the intrinsic union-of-manifold structures and lowering the complexity of the latent/target distribution. In this paper, we exploit the multimodality aspect of the union-of-manifold structures, and aim to further improve the learning and inference efficiency for flow-matching models. To this end, we propose an efficient source and coupling co-design method termed Mixture-Modeling Flow Matching (MM-FM), by integrating a data-adaptive multimodal source distribution (implemented as Gaussian mixture models) and mode-dependent data coupling. The former shortens the distance between the source and the target, and the latter promotes local and straighter flows. We also derive theoretical results to confirm our intuition in a quantitative sense. In our experiments on ImageNet256x256 with multimodal DINOv2-B latents, MM-FM exhibits superior learning efficiency and state-of-the-art unconditional generation quality: FID=2.74 with autoguidance in only 80 epochs.
@inproceedings{Luo_2026_CVPR,author={Luo, Gaoxiang and Cole, Frank and Zhang, Sihang and Wan, Yuxiang and Lu, Yulong and Sun, Ju},title={Flow Matching for Multimodal Distributions},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},month=jun,year={2026},pages={23260-23271},media={https://cse.umn.edu/cs/news/gaoxiang-luo-advances-efficient-generative-ai-research}}
CHI’26
MetaMate: Understanding How Educational Researchers Experience AI-Assisted Data Extraction for Systematic Reviews
Systematic reviews are essential for evidence synthesis in education, yet data extraction remains a bottleneck: labor-intensive and error-prone. Large language models offer automation potential, but questions remain about AI performance compared to human coders and how researchers experience these tools in practice. We present MetaMate, an open-access web-based tool for automated data extraction in educational systematic reviews. Our mixed-methods evaluation combines a quantitative validation study benchmarking MetaMate against trained human coders across 32 studies and 20 data elements with a qualitative user study involving six educational researchers using think-aloud protocols. MetaMate achieves precision (81–96%), recall (90–100%), and F1 scores (88–96%) comparable to or exceeding human coders, with strengths in mathematical reasoning and semantic comprehension. Qualitative findings reveal insights about trust calibration, verification behaviors, usability challenges, and human-AI collaboration. We contribute empirical evidence on LLM extraction capabilities and design implications for AI-assisted research tools balancing automation with human oversight. MetaMate is available at https://metamate.online.
@inproceedings{10.1145/3772363.3798755,author={Luo, Gaoxiang and Wang, Xue},title={MetaMate: Understanding How Educational Researchers Experience AI-Assisted Data Extraction for Systematic Reviews},year={2026},isbn={9798400722813},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3772363.3798755},doi={10.1145/3772363.3798755},booktitle={Proceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems},articleno={464},numpages={8},keywords={Large language models; systematic review; meta-analysis; data extraction; human-AI collaboration; trust calibration; educational research; AI-assisted tools},location={Barcelona, Spain},series={CHI EA '26},media={https://cse.umn.edu/cs/news/cse-excels-2026-acm-sigchi-conference-13-accepted-papers}}
Nature
A benchmark of expert-level academic questions to assess AI capabilities
Center AI Safety, Scale AI, and HLE Contributors Consortium
Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve more than 90% accuracy on popular benchmarks such as Measuring Massive Multitask Language Understanding1, limiting informed measurement of state-of-the-art LLM capabilities. Here, in response, we introduce Humanity’s Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be an expert-level closed-ended academic benchmark with broad subject coverage. HLE consists of 2,500 questions across dozens of subjects, including mathematics, humanities and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable but cannot be quickly answered by internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a marked gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
@article{Phan2026,author={AI Safety, Center and AI, Scale and Consortium, HLE Contributors},title={A benchmark of expert-level academic questions to assess AI capabilities},journal={Nature},year={2026},month=jan,day={01},volume={649},number={8099},pages={1139-1146},issn={1476-4687},doi={10.1038/s41586-025-09962-4},url={https://doi.org/10.1038/s41586-025-09962-4},}
Report
Improving Evidence Synthesis with Artificial Intelligence
Amir Mehr, Joshua Howard, Cyrus Nouroozi, Behrad Khorramnazari , and 12 more authors
Scientific knowledge is represented by approximately 3.3 million new journal articles each year and is expanding at an unprecedented pace, increasing in total size by 59% between 2012 and 2022. Systematic reviews and meta-analyses provide a structured means of evidence synthesis, but they are slow and labor-intensive, often requiring more than a year to complete. This bottleneck constrains scientific progress and is especially consequential in contexts such as public health crises (e.g., the COVID-19 pandemic), where timely evidence is essential for guiding policy and practice. Here we show that artificial intelligence methods can substantially improve both the efficiency and accuracy of systematic reviews. Using diverse datasets and examining over 30,000 data points, our AI-assisted approach matched or exceeded human performance while greatly reducing the risk of overlooking relevant evidence. In multiple tests of screening performance, the AI achieved 97.2% sensitivity and 96.84% specificity. With respect to extraction, the AI obtained 96.96% extraction accuracy, outperforming human efforts, and completed tasks up to 99% faster. These results demonstrate that AI augmentation can enable more timely and comprehensive evidence synthesis, facilitate living systematic reviews, and better support researchers, policymakers, and practitioners in responding to fast-moving scientific developments. Integrating AI into evidence synthesis represents a decisive advance in the accumulation of scientific knowledge.
@misc{mehrimproving,title={Improving Evidence Synthesis with Artificial Intelligence},author={Mehr, Amir and Howard, Joshua and Nouroozi, Cyrus and Khorramnazari, Behrad and Banks, George Christopher and Tay, Louis and Cuijpers, Pim and Miguel, Clara and Harrer, Mathias and Meyer, John P. and Stanley, David and Wang, Xue and Luo, Gaoxiang and Huo, Bright and Liu, Jason and Rousseau, Denise},doi={10.31222/osf.io/6d2wm_v1},publisher={MetaArXiv},year={2026},month=jan,}
2025
EMNLP’25
COM-BOM: Bayesian Exemplar Search for Efficiently Exploring the Accuracy-Calibration Pareto Frontier
Selecting an optimal set of exemplars is critical for good performance of in-context learning. However, prior exemplar search methods narrowly optimize for predictive accuracy, critically neglecting model calibration—a key determinant of trustworthiness and safe deployment. In this paper, we formulate exemplar selection as a multi-objective optimization problem, explicitly targeting both the maximization of predictive accuracy and the minimization of expected calibration error. We solve this problem with a sample-efficient Combinatorial Bayesian Optimization algorithm (COM-BOM) to find the Pareto-front that optimally trade-offs the two objectives of accuracy and calibration. We evaluate COM-BOM on multiple tasks from un-saturated MMLU-pro benchmark and find that COM-BOM beats or matches the baselines in jointly optimizing the two objectives, while requiring a minimal number of LLM API calls.
@inproceedings{luo-deshwal-2025-com,title={{COM}-{BOM}: {B}ayesian Exemplar Search for Efficiently Exploring the Accuracy-Calibration {P}areto Frontier},author={Luo, Gaoxiang and Deshwal, Aryan},editor={Christodoulopoulos, Christos and Chakraborty, Tanmoy and Rose, Carolyn and Peng, Violet},booktitle={Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing},month=nov,year={2025},address={Suzhou, China},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2025.emnlp-main.1027/},pages={20350--20363},isbn={979-8-89176-332-6},media={https://cse.umn.edu/cs/news/gaoxiang-luo-advances-efficient-generative-ai-research}}
JNSP
Automated ventricular segmentation in pediatric hydrocephalus: how close are we?
Birra R. Taha, Gaoxiang Luo, Anant Naik, Luke Sabal , and 4 more authors
OBJECTIVE: The explosive growth of available high-quality imaging data coupled with new progress in hardware capabilities has enabled a new era of unprecedented performance in brain segmentation tasks. Despite the explosion of new data released by consortiums and groups around the world, most published, closed, or openly available segmentation models have either a limited or an unknown role in pediatric brains. This study explores the utility of state-of-the-art automated ventricular segmentation tools applied to pediatric hydrocephalus. Two popular, fast, whole-brain segmentation tools were used (FastSurfer and QuickNAT) to automatically segment the lateral ventricles and evaluate their accuracy in children with hydrocephalus. METHODS: Forty scans from 32 patients were included in this study. The patients underwent imaging at the University of Minnesota Medical Center or satellite clinics, were between 0 and 18 years old, had an ICD-10 diagnosis that included the word hydrocephalus, and had at least one T1-weighted pre- or postcontrast MPRAGE sequence. Patients with poor quality scans were excluded. Dice similarity coefficient (DSC) scores were used to compare segmentation outputs against manually segmented lateral ventricles. RESULTS:Overall, both models performed poorly with DSCs of 0.61 for each segmentation tool. No statistically significant difference was noted between model performance (p = 0.86). Using a multivariate linear regression to examine factors associated with higher DSC performance, male gender (p = 0.66), presence of ventricular catheter (p = 0.72), and MRI magnet strength (p = 0.23) were not statistically significant factors. However, younger age (p = 0.03) and larger ventricular volumes (p = 0.01) were significantly associated with lower DSC values. A large-scale visualization of 196 scans in both models showed characteristic patterns of segmentation failure in larger ventricles. CONCLUSIONS:Significant gaps exist in current cutting-edge segmentation models when applied to pediatric hydrocephalus. Researchers will need to address these types of gaps in performance through thoughtful consideration of their training data before reaching the ultimate goal of clinical deployment.
@article{10.3171/2025.2.PEDS24590,author={Taha, Birra R. and Luo, Gaoxiang and Naik, Anant and Sabal, Luke and Sun, Ju and McGovern, Robert A. and Sandoval-Garcia, Carolina and Guillaume, Daniel J.},title={Automated ventricular segmentation in pediatric hydrocephalus: how close are we?},journal={Journal of Neurosurgery: Pediatrics},year={2025},publisher={American Association of Neurological Surgeons},doi={10.3171/2025.2.PEDS24590},pages={1 - 8},url={https://doi.org/10.3171/2025.2.PEDS24590},}
CHI’25
Empowering Farming Communities Through Information Tracking: A Design Approach to Crop Planning and Management
Agriculture is a key sector in the U.S. economy, supporting not only farmers but also industries like food processing and transportation. Due to labor shortages and an aging population, immigrant farmers have become essential to the workforce. However, they face challenges such as outdated tools, reliance on family labor, and uncertain land leases, contributing to economic insecurity. Additionally, their low literacy levels often result in ineffective tracking of crucial information, leading to missed opportunities in crop disease management and budget planning. Through interviews with 7 immigrant farmers and prototyping, we explored their everyday farming practices and identified opportunities for improved record-keeping. Our findings suggest that improved information tracking could facilitate learning, crop management, and community support. This research informs the design of self-tracking technologies tailored to farmers, offering insights into culturally relevant solutions. Based on these findings, the team will develop and deploy a high-fidelity prototype on local farms.
@inproceedings{10.1145/3706599.3719713,author={Chen, Zhanming and Lu, Minghe and Zhao, Minzhu and Luo, Gaoxiang and Withey, Benjamin and Yong, Seraphina and Shin, Ji Youn},title={Empowering Farming Communities Through Information Tracking: A Design Approach to Crop Planning and Management},year={2025},isbn={9798400713958},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3706599.3719713},doi={10.1145/3706599.3719713},booktitle={Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems},articleno={217},numpages={8},keywords={Agriculture, farming, immigrant, community, information management, self-tracking, design},location={Yokohama, Japan},series={CHI EA '25},}
@inproceedings{10.1145/3636534.3649369,author={Lai, Haowen and Luo, Gaoxiang and Liu, Yifei and Zhao, Mingmin},title={Enabling Visual Recognition at Radio Frequency},year={2024},isbn={9798400704895},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3636534.3649369},doi={10.1145/3636534.3649369},booktitle={Proceedings of the 30th Annual International Conference on Mobile Computing and Networking},pages={388–403},numpages={16},keywords={RF sensing, mmWave radar, egomotion estimation, 3D imaging, robust perception, machine learning},location={Washington D.C., DC, USA},series={ACM MobiCom '24},media={https://www.bbc.com/news/articles/cm2l1y73mz1o},}
npj Digital Medicine
An in-depth evaluation of federated learning on biomedical natural language processing for information extraction
Language models (LMs) such as BERT and GPT have revolutionized natural language processing (NLP). However, the medical field faces challenges in training LMs due to limited data access and privacy constraints imposed by regulations like the Health Insurance Portability and Accountability Act (HIPPA) and the General Data Protection Regulation (GDPR). Federated learning (FL) offers a decentralized solution that enables collaborative learning while ensuring data privacy. In this study, we evaluated FL on 2 biomedical NLP tasks encompassing 8 corpora using 6 LMs. Our results show that: (1) FL models consistently outperformed models trained on individual clients’ data and sometimes performed comparably with models trained with polled data; (2) with the fixed number of total data, FL models training with more clients produced inferior performance but pre-trained transformer-based models exhibited great resilience. (3) FL models significantly outperformed pre-trained LLMs with few-shot prompting.
@article{Peng2024,author={Peng, Le and Luo, Gaoxiang and Zhou, Sicheng and Chen, Jiandong and Xu, Ziyue and Sun, Ju and Zhang, Rui},title={An in-depth evaluation of federated learning on biomedical natural language processing for information extraction},journal={npj Digital Medicine},year={2024},month=may,day={15},volume={7},number={1},pages={127},issn={2398-6352},doi={10.1038/s41746-024-01126-4},url={https://doi.org/10.1038/s41746-024-01126-4},}
SREE’24, AREA’25, SREE’25
MetaMate: Large Language Model to the Rescue of Automated Data Extraction for Educational Systematic Reviews and Meta-analyses
Systematic reviews and meta-analyses are crucial for synthesizing evidence but are time-consuming and labor-intensive, especially during data extraction. To address this challenge, we developed MetaMate, an open-access web-based tool leveraging large language models (LLMs) for automated data extraction in educational systematic reviews and meta-analyses. MetaMate utilizes a hierarchical schema and divide-and-conquer approach in its extraction chain, and a from-global-to-local lens and example retriever in its verification chain. We evaluated MetaMate’s performance on 32 empirical studies, extracting 20 data elements related to participants and interventions. MetaMate achieved high precision, recall, and F1 scores, with performance comparable to human coders when benchmarked against an expert-defined gold standard. Notably, MetaMate demonstrated advanced mathematical reasoning and semantic comprehension, surpassing keyword-based approaches and avoiding common human errors. As the first LLM-powered data extraction tool designed specifically for educational research, MetaMate has the potential to significantly streamline the systematic review process and reduce time and effort for researchers. MetaMate is available at https://metamate.online.
@misc{wang_luo_2024,title={MetaMate: Large Language Model to the Rescue of Automated Data Extraction for Educational Systematic Reviews and Meta-analyses},url={osf.io/preprints/edarxiv/wn3cd},doi={10.35542/osf.io/wn3cd},publisher={EdArXiv},author={Wang, Xue and Luo, Gaoxiang},year={2024},month=may,}
2023
BMVC’23
Rethinking Transfer Learning for Medical Image Classification
Transfer learning (TL) from pretrained deep models is a standard practice in modern medical image classification (MIC). However, what levels of features to be reused are problem-dependent, and uniformly finetuning all layers of pretrained models may be suboptimal. This insight has partly motivated the recent differential TL strategies, such as TransFusion (TF) and layer-wise finetuning (LWFT), which treat the layers in the pretrained models differentially. In this paper, we add one more strategy into this family, called TruncatedTL, which reuses and finetunes appropriate bottom layers and directly discards the remaining layers. This yields not only superior MIC performance but also compact models for efficient inference, compared to other differential TL methods. Our code is available at: https://github.com/sun-umn/TTL
@inproceedings{peng2023rethinking,title={Rethinking Transfer Learning for Medical Image Classification},author={Peng, Le and Liang, Hengyue and Luo, Gaoxiang and Li, Taihui and Sun, Ju},year={2023},publisher={British Machine Vision Association},booktitle={Proceedings of the 34th British Machine Vision Conference,},series={BMVC '23},location={Aberdeen, UK},url={https://papers.bmvc2023.org/0881.pdf},}
JMI
Ability of artificial intelligence to identify self-reported race in chest x-ray using pixel intensity counts
PurposePrior studies show convolutional neural networks predicting self-reported race using x-rays of chest, hand and spine, chest computed tomography, and mammogram. We seek an understanding of the mechanism that reveals race within x-ray images, investigating the possibility that race is not predicted using the physical structure in x-ray images but is embedded in the grayscale pixel intensities.ApproachRetrospective full year 2021, 298,827 AP/PA chest x-ray images from 3 academic health centers across the United States and MIMIC-CXR, labeled by self-reported race, were used in this study. The image structure is removed by summing the number of each grayscale value and scaling to percent per image (PPI). The resulting data are tested using multivariate analysis of variance (MANOVA) with Bonferroni multiple-comparison adjustment and class-balanced MANOVA. Machine learning (ML) feed-forward networks (FFN) and decision trees were built to predict race (binary Black or White and binary Black or other) using only grayscale value counts. Stratified analysis by body mass index, age, sex, gender, patient type, make/model of scanner, exposure, and kilovoltage peak setting was run to study the impact of these factors on race prediction following the same methodology.ResultsMANOVA rejects the null hypothesis that classes are the same with 95% confidence (F 7.38, P < 0.0001) and balanced MANOVA (F 2.02, P < 0.0001). The best FFN performance is limited [area under the receiver operating characteristic (AUROC) of 69.18%]. Gradient boosted trees predict self-reported race using grayscale PPI (AUROC 77.24%).ConclusionsWithin chest x-rays, pixel intensity value counts alone are statistically significant indicators and enough for ML classification tasks of patient self-reported race.
@article{10.1117/1.JMI.10.6.061106,author={Burns, John Lee and Zaiman, Zachary and Vanschaik, Jack and Luo, Gaoxiang and Peng, Le and Price, Brandon and Mathias, Garric and Mittal, Vijay and Sagane, Akshay and Tignanelli, Christopher and Chakraborty, Sunandan and Gichoya, Judy W. and Purkayastha, Saptarshi},title={{Ability of artificial intelligence to identify self-reported race in chest x-ray using pixel intensity counts}},volume={10},journal={Journal of Medical Imaging},number={6},publisher={SPIE},pages={061106},keywords={machine learning, bias, population imaging, x-ray, Artificial intelligence, Data modeling, Chest imaging, Binary data, Brain-machine interfaces, X-rays, Machine learning, Decision trees, Education and training, Performance modeling},year={2023},doi={10.1117/1.JMI.10.6.061106},url={https://doi.org/10.1117/1.JMI.10.6.061106},}
2022
JAMIA
Evaluation of federated learning variations for COVID-19 diagnosis using chest radiographs from 42 US and European hospitals
Federated learning (FL) allows multiple distributed data holders to collaboratively learn a shared model without data sharing. However, individual health system data are heterogeneous. “Personalized” FL variations have been developed to counter data heterogeneity, but few have been evaluated using real-world healthcare data. The purpose of this study is to investigate the performance of a single-site versus a 3-client federated model using a previously described Coronavirus Disease 19 (COVID-19) diagnostic model. Additionally, to investigate the effect of system heterogeneity, we evaluate the performance of 4 FL variations.We leverage a FL healthcare collaborative including data from 5 international healthcare systems (US and Europe) encompassing 42 hospitals. We implemented a COVID-19 computer vision diagnosis system using the Federated Averaging (FedAvg) algorithm implemented on Clara Train SDK 4.0. To study the effect of data heterogeneity, training data was pooled from 3 systems locally and federation was simulated. We compared a centralized/pooled model, versus FedAvg, and 3 personalized FL variations (FedProx, FedBN, and FedAMP).We observed comparable model performance with respect to internal validation (local model: AUROC 0.94 vs FedAvg: 0.95, P = .5) and improved model generalizability with the FedAvg model (P \< .05). When investigating the effects of model heterogeneity, we observed poor performance with FedAvg on internal validation as compared to personalized FL algorithms. FedAvg did have improved generalizability compared to personalized FL algorithms. On average, FedBN had the best rank performance on internal and external validation.FedAvg can significantly improve the generalization of the model compared to other personalization FL algorithms; however, at the cost of poor internal validity. Personalized FL may offer an opportunity to develop both internal and externally validated algorithms.
@article{10.1093/jamia/ocac188,author={Peng, Le and Luo, Gaoxiang and Walker, Andrew and Zaiman, Zachary and Jones, Emma K and Gupta, Hemant and Kersten, Kristopher and Burns, John L and Harle, Christopher A and Magoc, Tanja and Shickel, Benjamin and Steenburg, Scott D and Loftus, Tyler and Melton, Genevieve B and Gichoya, Judy Wawira and Sun, Ju and Tignanelli, Christopher J},title={{Evaluation of federated learning variations for COVID-19 diagnosis using chest radiographs from 42 US and European hospitals}},journal={Journal of the American Medical Informatics Association},volume={30},number={1},pages={54-63},year={2022},month=oct,issn={1527-974X},doi={10.1093/jamia/ocac188},url={https://doi.org/10.1093/jamia/ocac188},eprint={https://academic.oup.com/jamia/article-pdf/30/1/54/47829262/ocac188.pdf},}
KDD’22
SAMCNet: Towards a Spatially Explainable AI Approach for Classifying MxIF Oncology Data
The goal of spatially explainable artificial intelligence (AI) classification approach is to build a classifier to distinguish two classes (e.g., responder, non-responder) based on the their spatial arrangements (e.g., spatial interactions between different point categories) given multi-category point data from two classes. This problem is important for generating hypotheses towards discovering new immunotherapies for cancer treatment as well as for other applications in biomedical research and microbial ecology. This problem is challenging due to an exponential number of category subsets which may vary in the strength of their spatial interactions. Most prior efforts on using human selected spatial association measures may not be sufficient for capturing the relevant spatial interactions (e.g., surrounded by) which may be of biological significance. In addition, the related deep neural networks are limited to category pairs and do not explore larger subsets of point categories. To overcome these limitations, we propose a Spatial-interaction Aware Multi-Category deep neural Network (SAMCNet) architecture and contribute novel local reference frame characterization and point pair prioritization layers for spatially explainable classification. Experimental results on multiple cancer datasets (e.g., MxIF) show that the proposed architecture provides higher prediction accuracy over baseline methods. A real-world case study demonstrates that the proposed work discovers patterns that are missed by the existing methods and has the potential to inspire new scientific discoveries.
@inproceedings{10.1145/3534678.3539168,author={Farhadloo, Majid and Molnar, Carl and Luo, Gaoxiang and Li, Yan and Shekhar, Shashi and Maus, Rachel L. and Markovic, Svetomir and Leontovich, Alexey and Moore, Raymond},title={SAMCNet: Towards a Spatially Explainable AI Approach for Classifying MxIF Oncology Data},year={2022},isbn={9781450393850},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3534678.3539168},doi={10.1145/3534678.3539168},booktitle={Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},pages={2860–2870},numpages={11},keywords={mxif, oncology, spatial interactions, spatially explainable classifier},location={Washington DC, USA},series={KDD '22},}
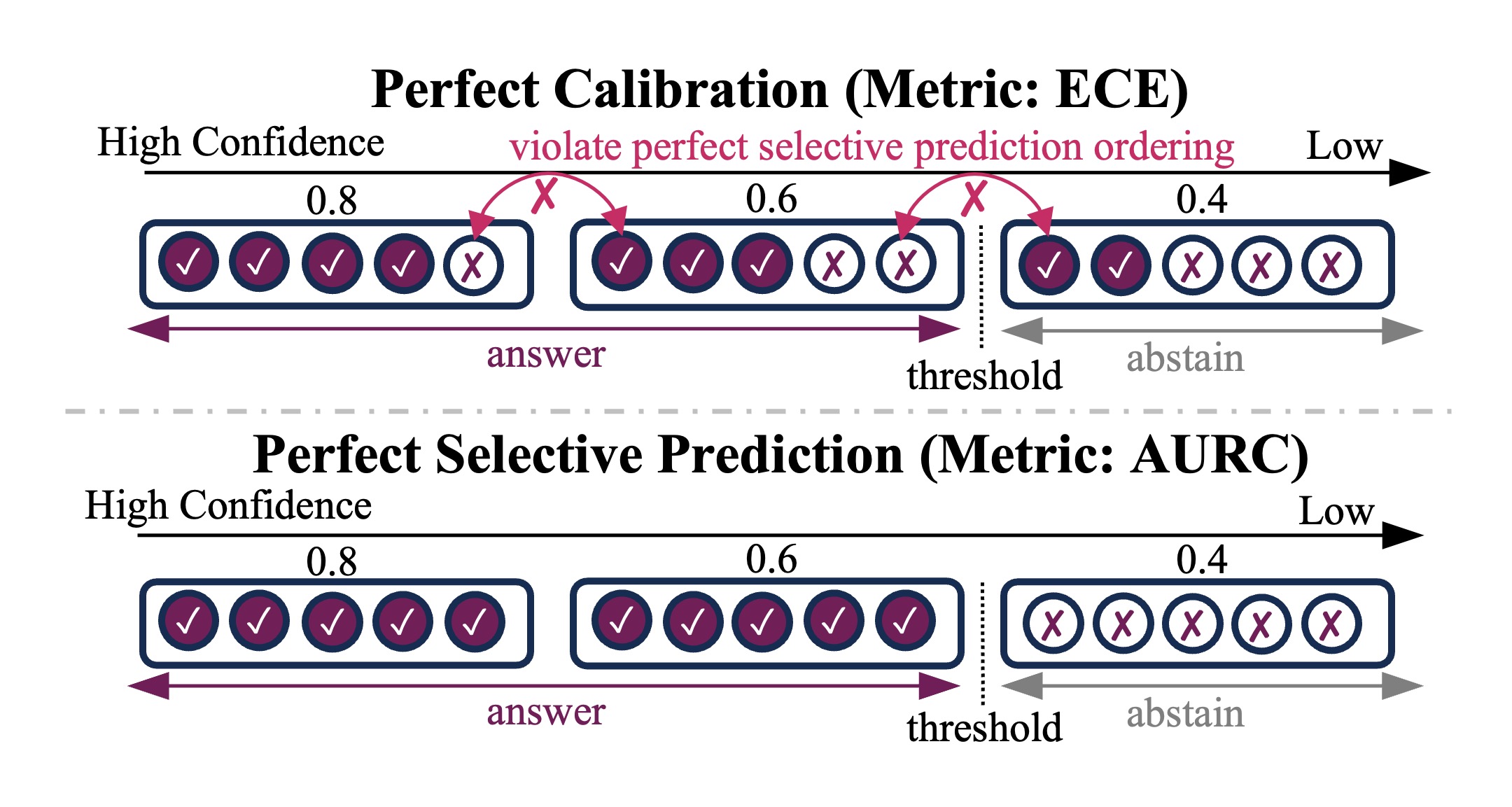 Aligning Language Models with Selective PredictionIn Forty-third International Conference on Machine Learning Second Workshop on Agents in the Wild: Safety, Security, and Beyond , 2026
Aligning Language Models with Selective PredictionIn Forty-third International Conference on Machine Learning Second Workshop on Agents in the Wild: Safety, Security, and Beyond , 2026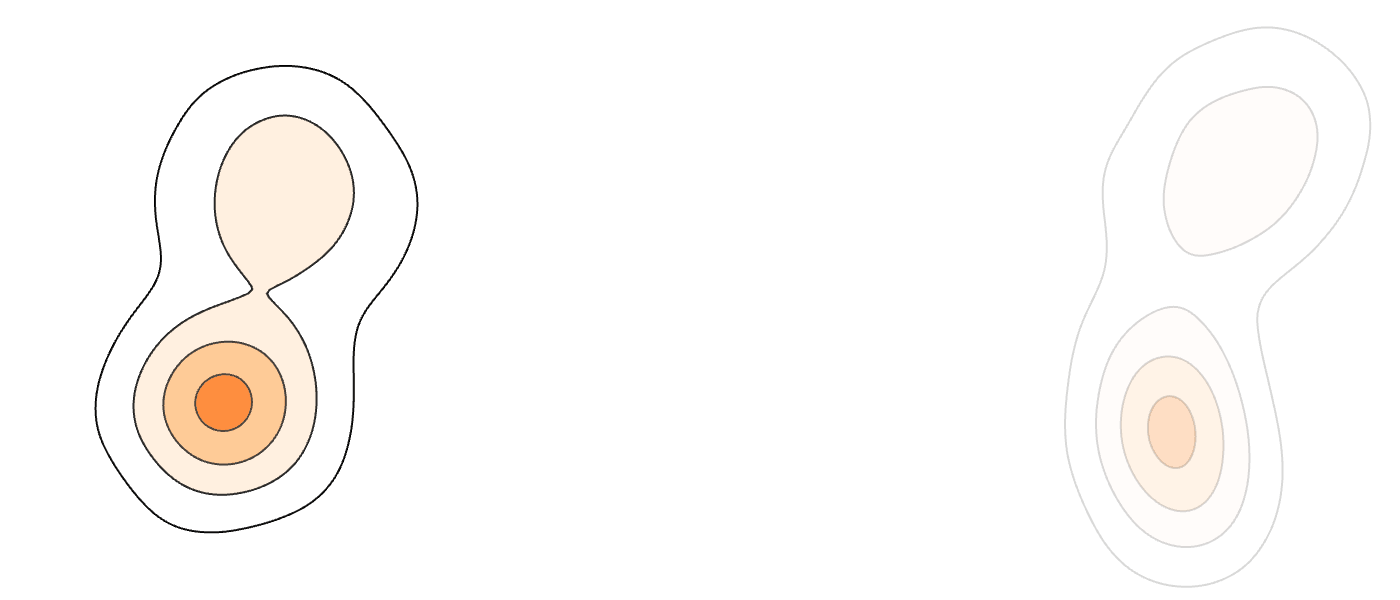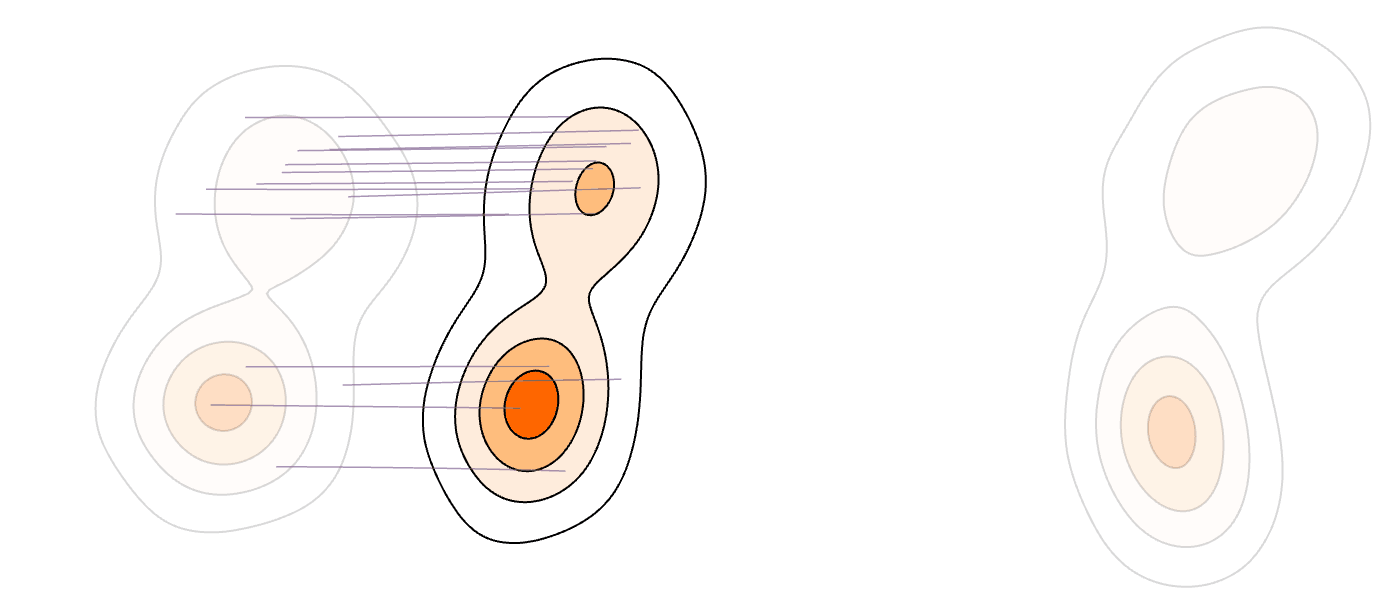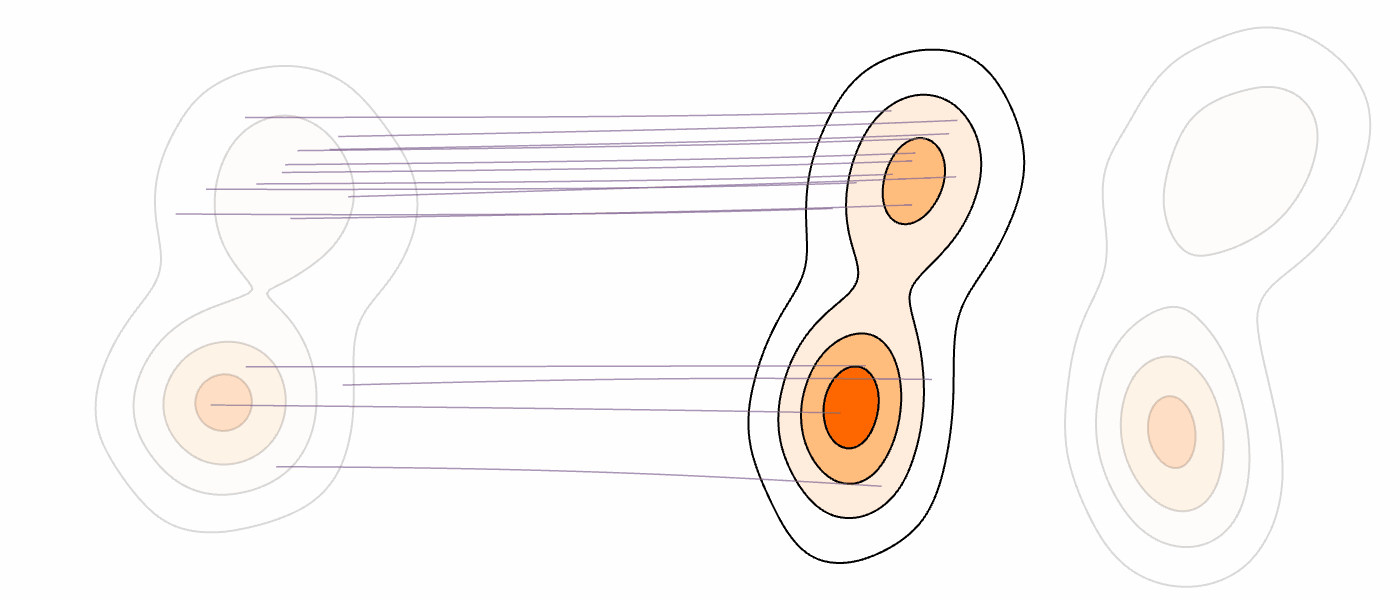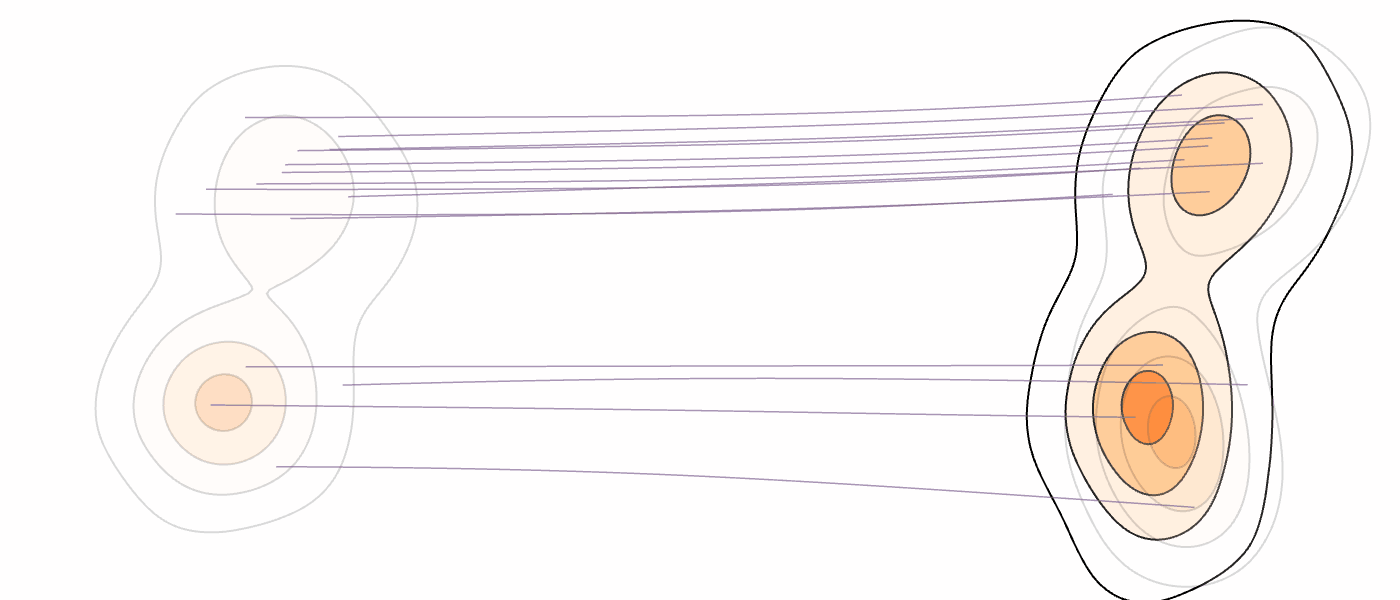 Flow Matching for Multimodal DistributionsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2026
Flow Matching for Multimodal DistributionsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2026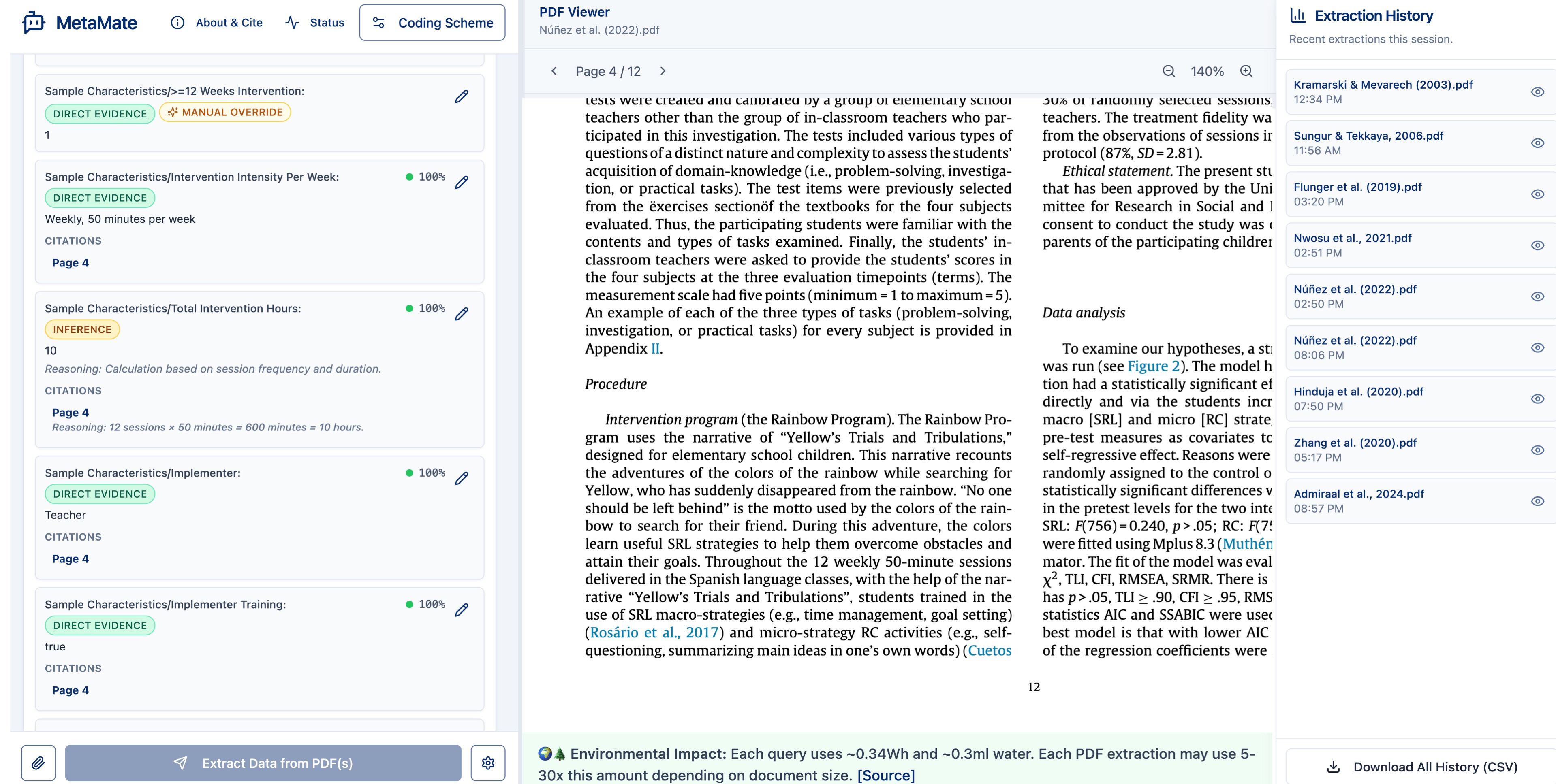 MetaMate: Understanding How Educational Researchers Experience AI-Assisted Data Extraction for Systematic ReviewsGaoxiang Luo*, and Xue Wang*In Proceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems , Barcelona, Spain, Jun 2026
MetaMate: Understanding How Educational Researchers Experience AI-Assisted Data Extraction for Systematic ReviewsGaoxiang Luo*, and Xue Wang*In Proceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems , Barcelona, Spain, Jun 2026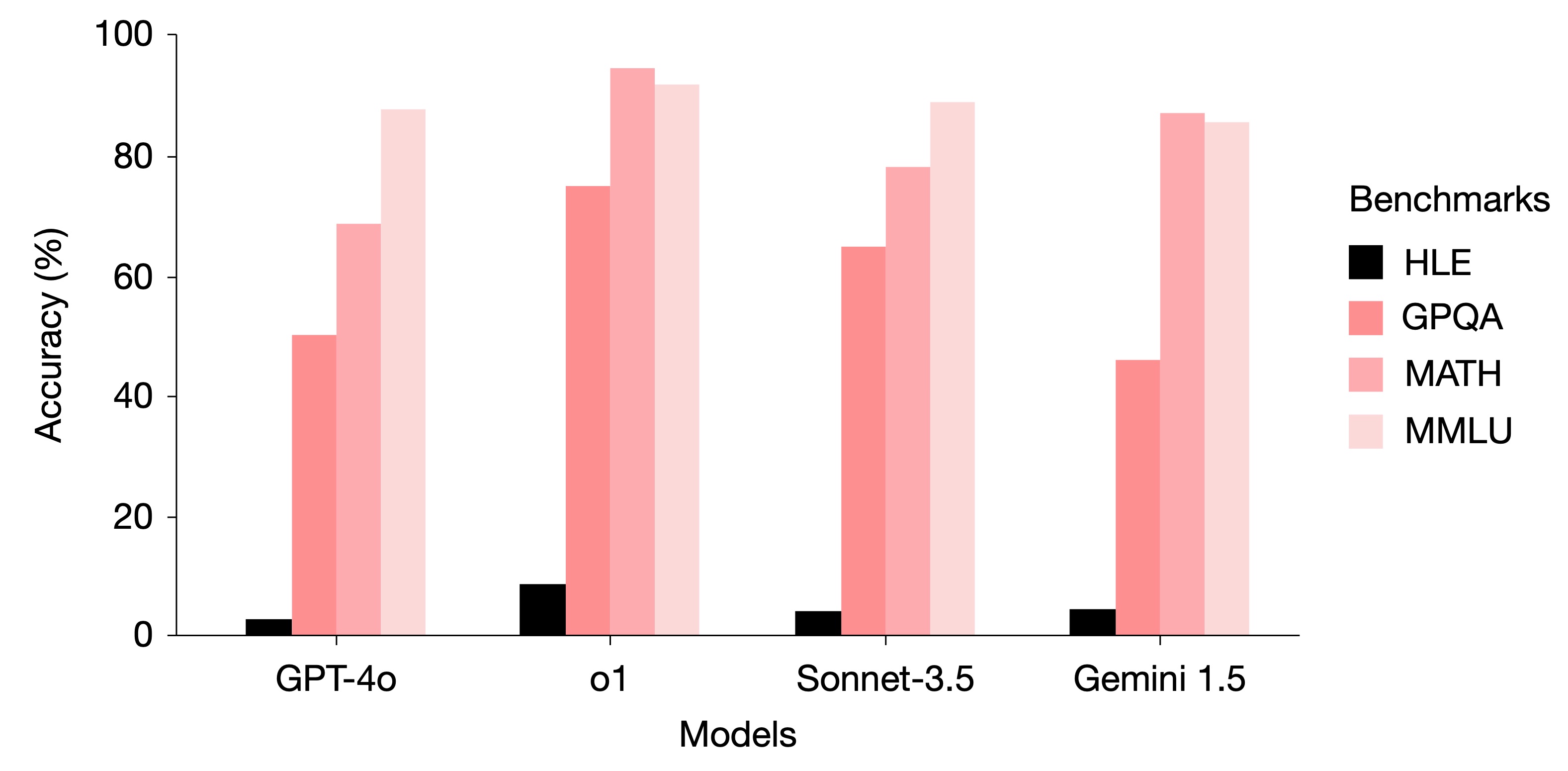 A benchmark of expert-level academic questions to assess AI capabilitiesCenter AI Safety, Scale AI, and HLE Contributors ConsortiumNature, Jan 2026
A benchmark of expert-level academic questions to assess AI capabilitiesCenter AI Safety, Scale AI, and HLE Contributors ConsortiumNature, Jan 2026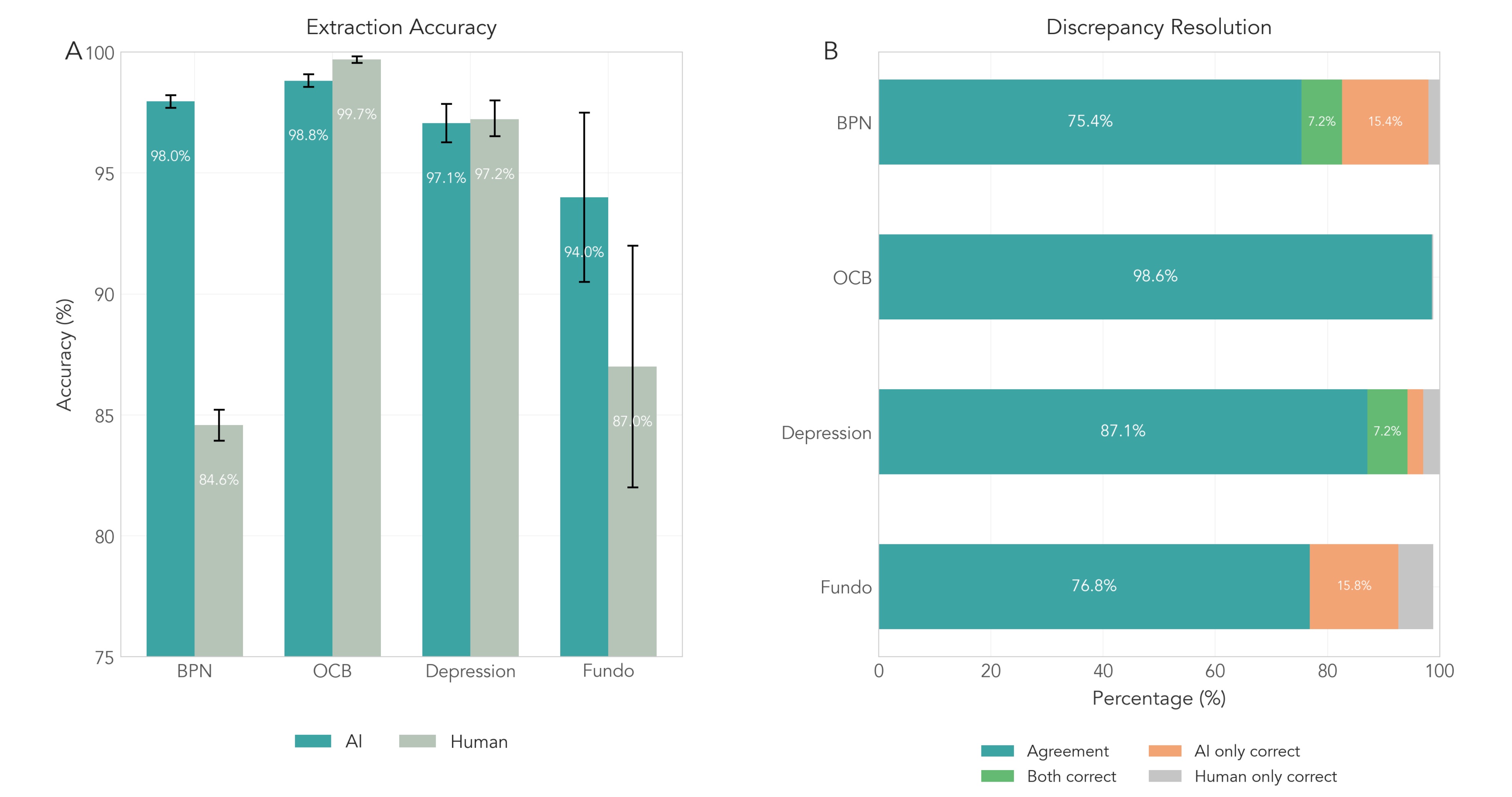 Improving Evidence Synthesis with Artificial IntelligenceAmir Mehr, Joshua Howard, Cyrus Nouroozi, Behrad Khorramnazari , and 12 more authorsJan 2026
Improving Evidence Synthesis with Artificial IntelligenceAmir Mehr, Joshua Howard, Cyrus Nouroozi, Behrad Khorramnazari , and 12 more authorsJan 2026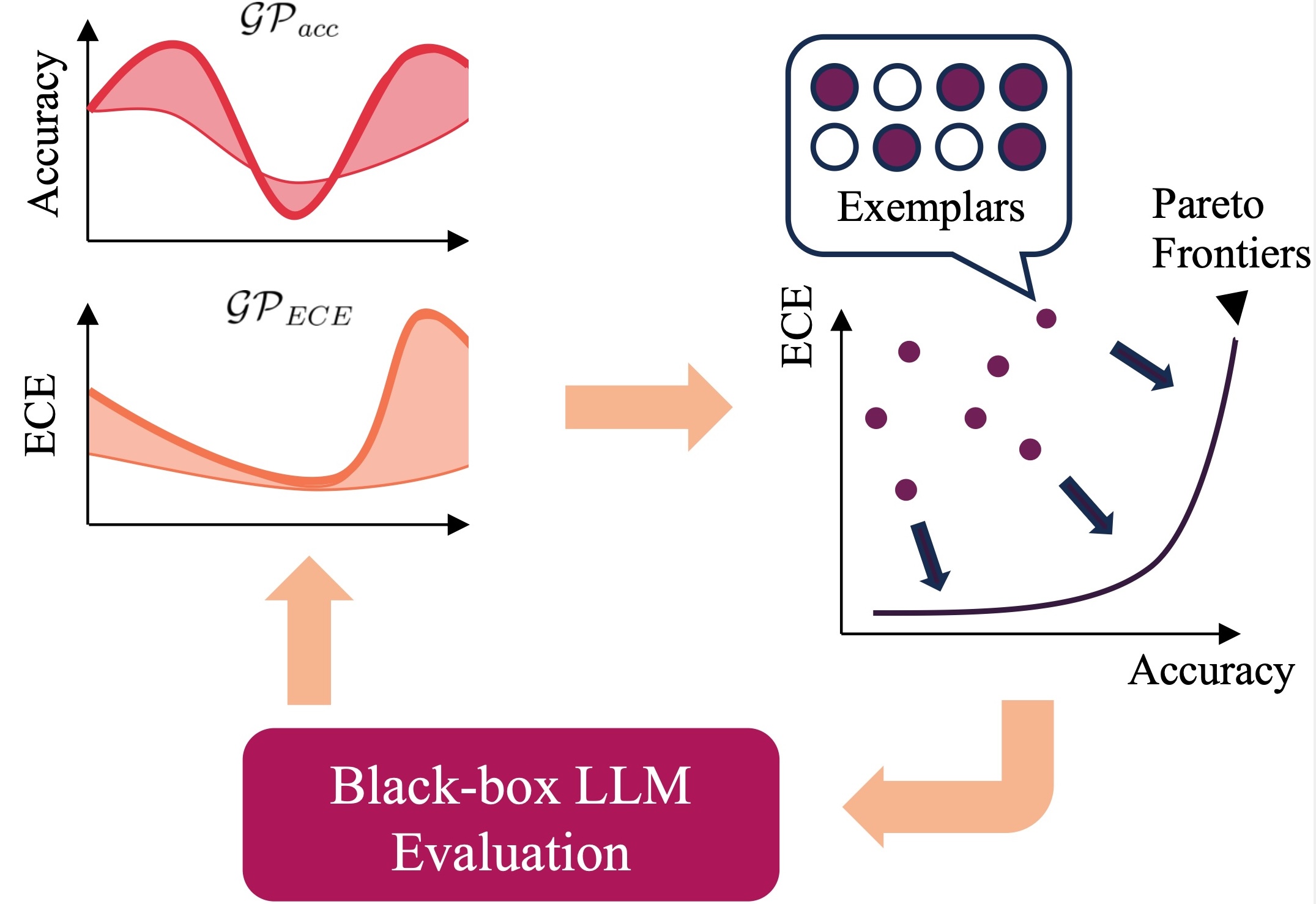 COM-BOM: Bayesian Exemplar Search for Efficiently Exploring the Accuracy-Calibration Pareto FrontierGaoxiang Luo, and Aryan DeshwalIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , Nov 2025
COM-BOM: Bayesian Exemplar Search for Efficiently Exploring the Accuracy-Calibration Pareto FrontierGaoxiang Luo, and Aryan DeshwalIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , Nov 2025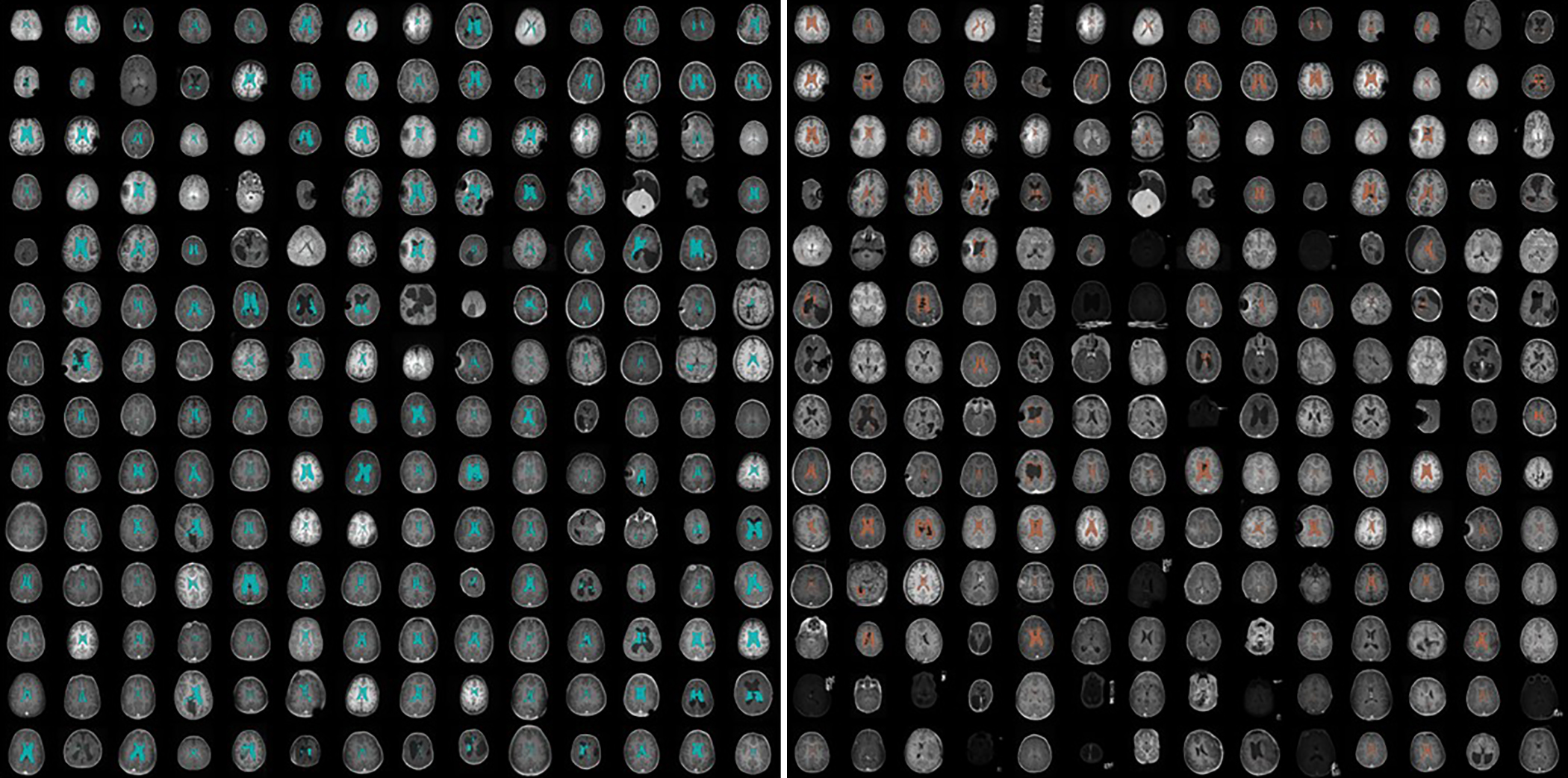 Automated ventricular segmentation in pediatric hydrocephalus: how close are we?Birra R. Taha, Gaoxiang Luo, Anant Naik, Luke Sabal , and 4 more authorsJournal of Neurosurgery: Pediatrics, Nov 2025
Automated ventricular segmentation in pediatric hydrocephalus: how close are we?Birra R. Taha, Gaoxiang Luo, Anant Naik, Luke Sabal , and 4 more authorsJournal of Neurosurgery: Pediatrics, Nov 2025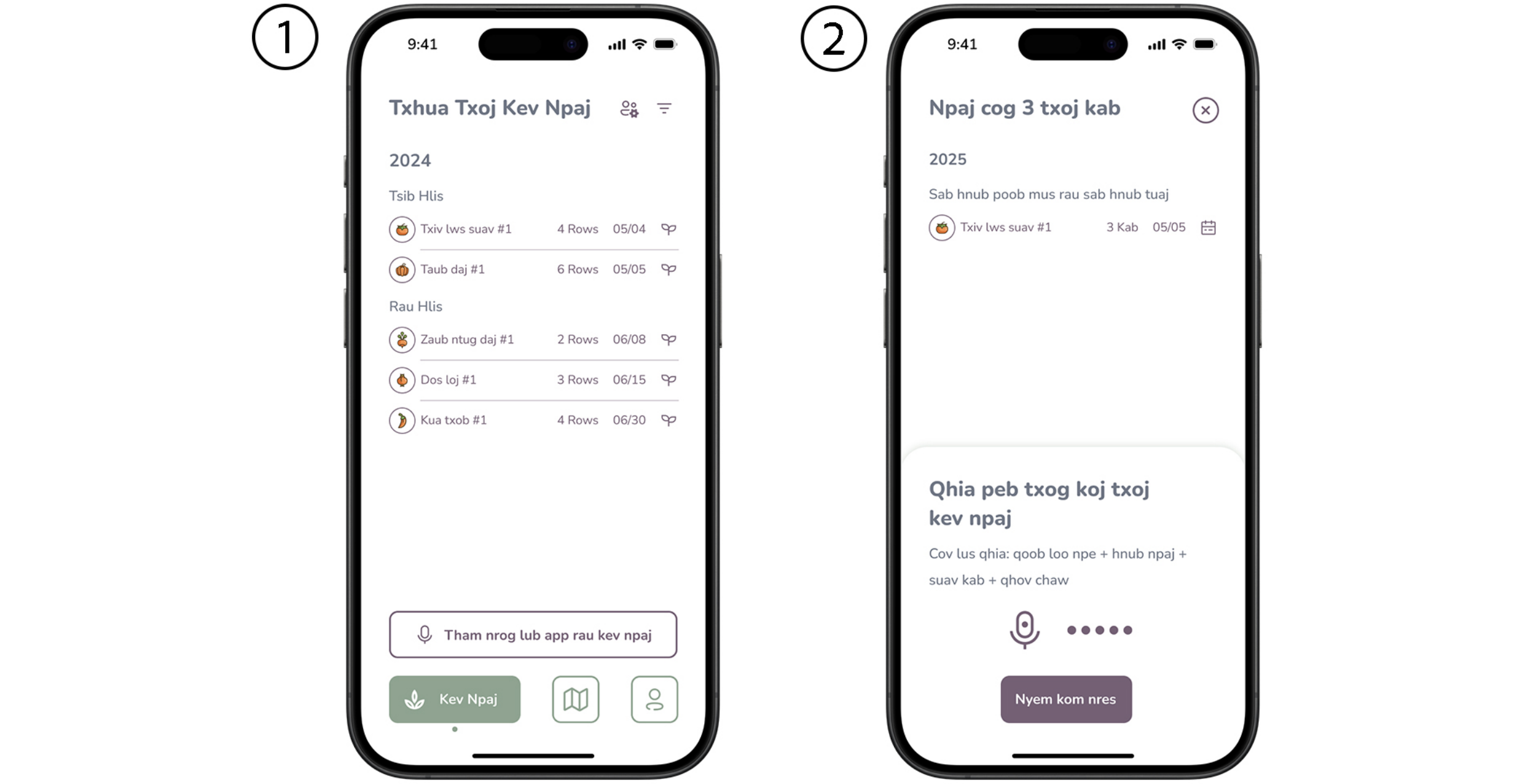 Empowering Farming Communities Through Information Tracking: A Design Approach to Crop Planning and ManagementIn Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , Yokohama, Japan, Nov 2025
Empowering Farming Communities Through Information Tracking: A Design Approach to Crop Planning and ManagementIn Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , Yokohama, Japan, Nov 2025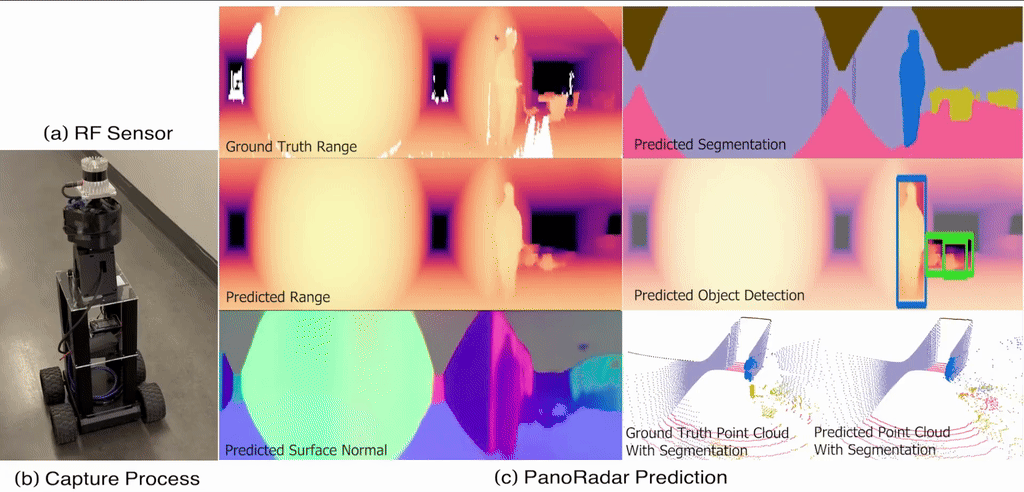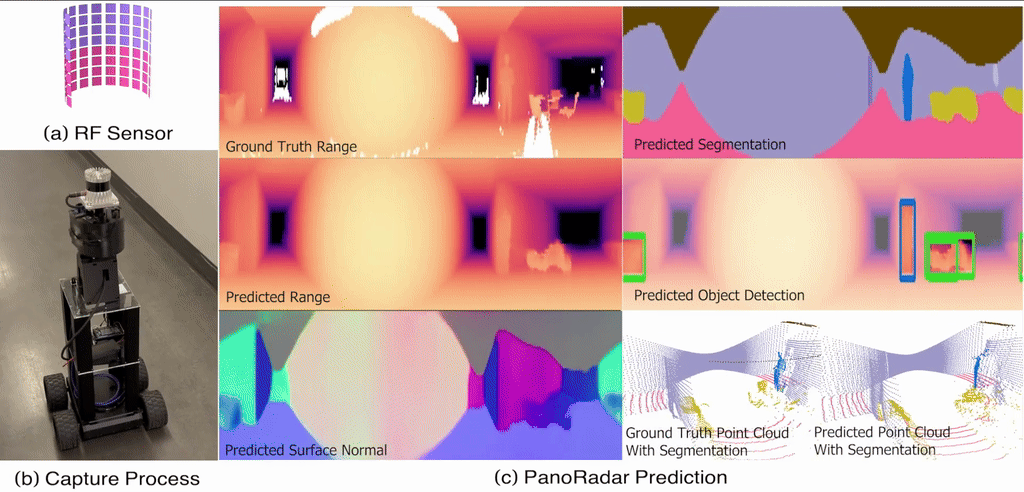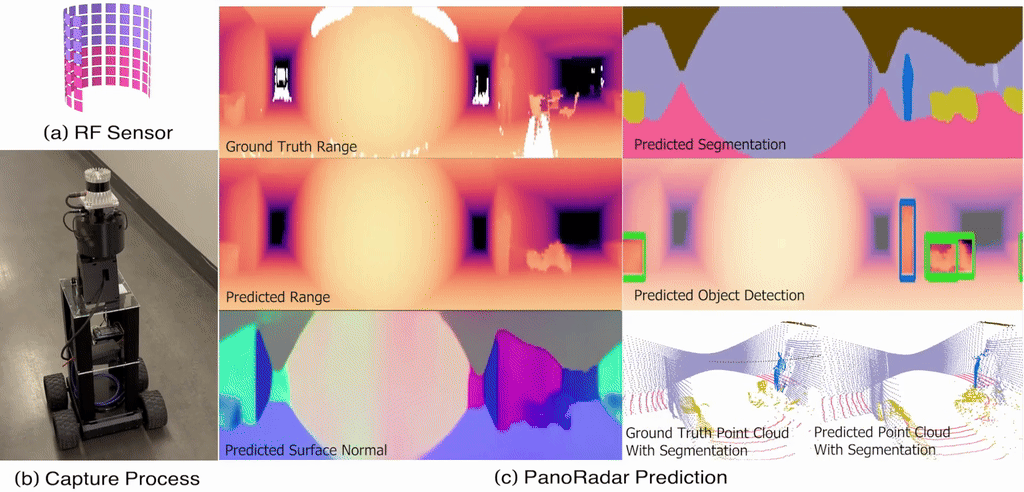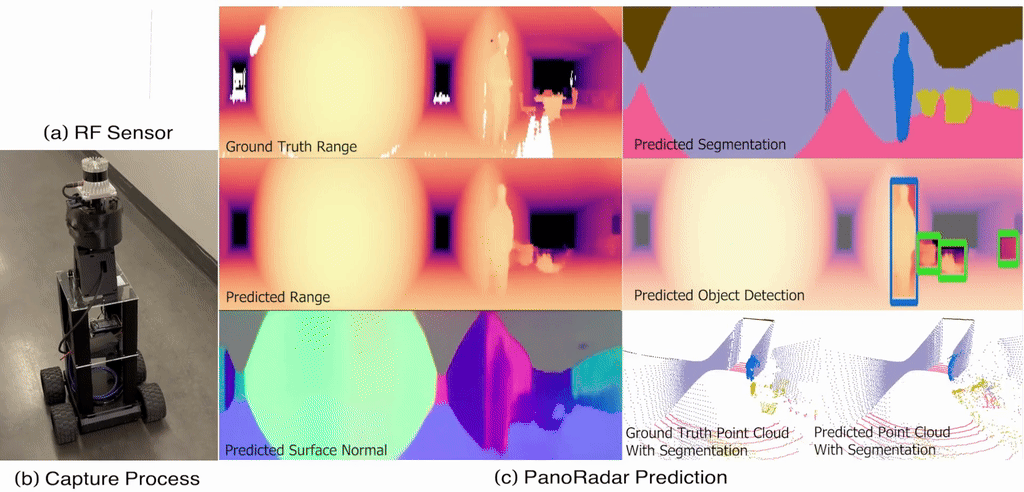 Enabling Visual Recognition at Radio FrequencyIn Proceedings of the 30th Annual International Conference on Mobile Computing and Networking , Washington D.C., DC, USA, Nov 2024
Enabling Visual Recognition at Radio FrequencyIn Proceedings of the 30th Annual International Conference on Mobile Computing and Networking , Washington D.C., DC, USA, Nov 2024



 An in-depth evaluation of federated learning on biomedical natural language processing for information extractionnpj Digital Medicine, May 2024
An in-depth evaluation of federated learning on biomedical natural language processing for information extractionnpj Digital Medicine, May 2024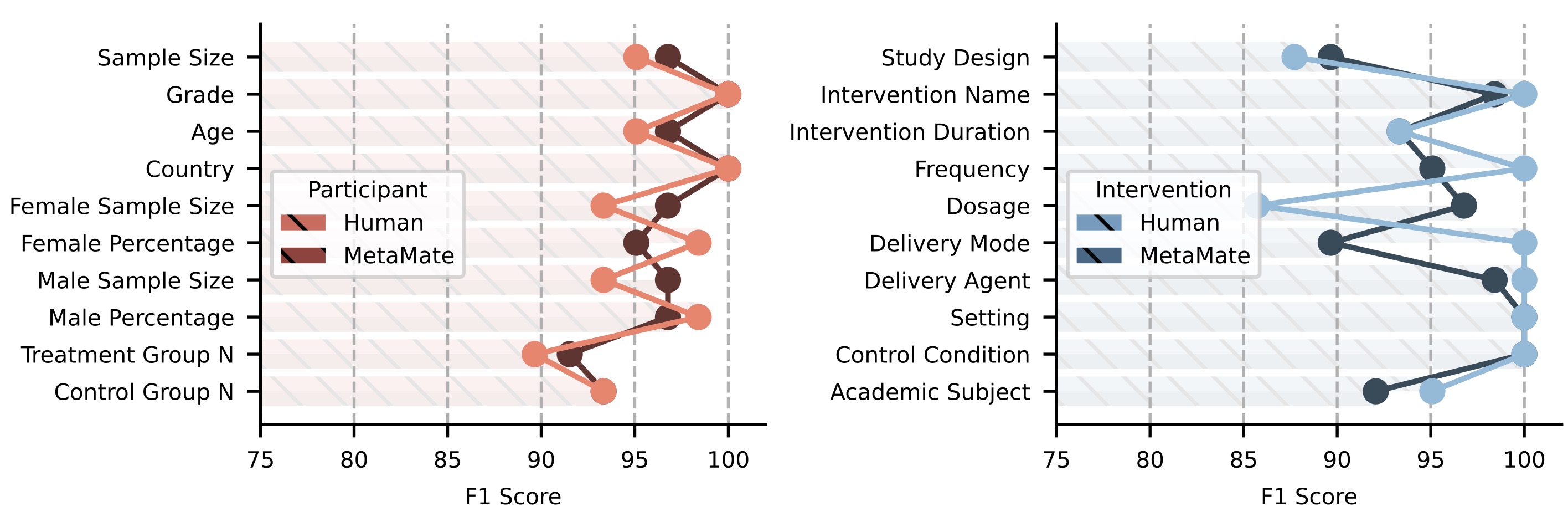 MetaMate: Large Language Model to the Rescue of Automated Data Extraction for Educational Systematic Reviews and Meta-analysesXue Wang*, and Gaoxiang Luo*May 2024
MetaMate: Large Language Model to the Rescue of Automated Data Extraction for Educational Systematic Reviews and Meta-analysesXue Wang*, and Gaoxiang Luo*May 2024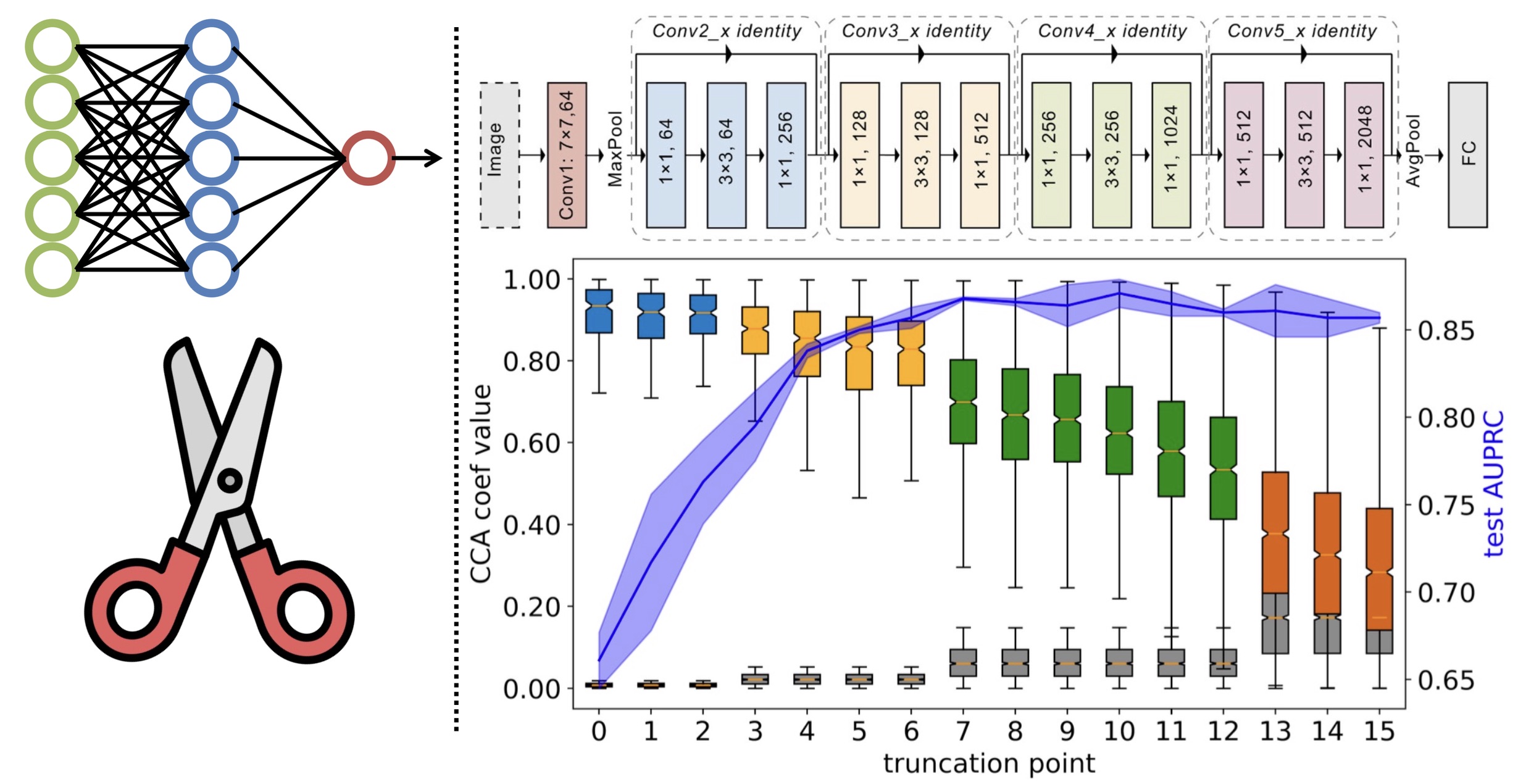 Rethinking Transfer Learning for Medical Image ClassificationIn Proceedings of the 34th British Machine Vision Conference, , Aberdeen, UK, May 2023
Rethinking Transfer Learning for Medical Image ClassificationIn Proceedings of the 34th British Machine Vision Conference, , Aberdeen, UK, May 2023 Ability of artificial intelligence to identify self-reported race in chest x-ray using pixel intensity countsJournal of Medical Imaging, May 2023
Ability of artificial intelligence to identify self-reported race in chest x-ray using pixel intensity countsJournal of Medical Imaging, May 2023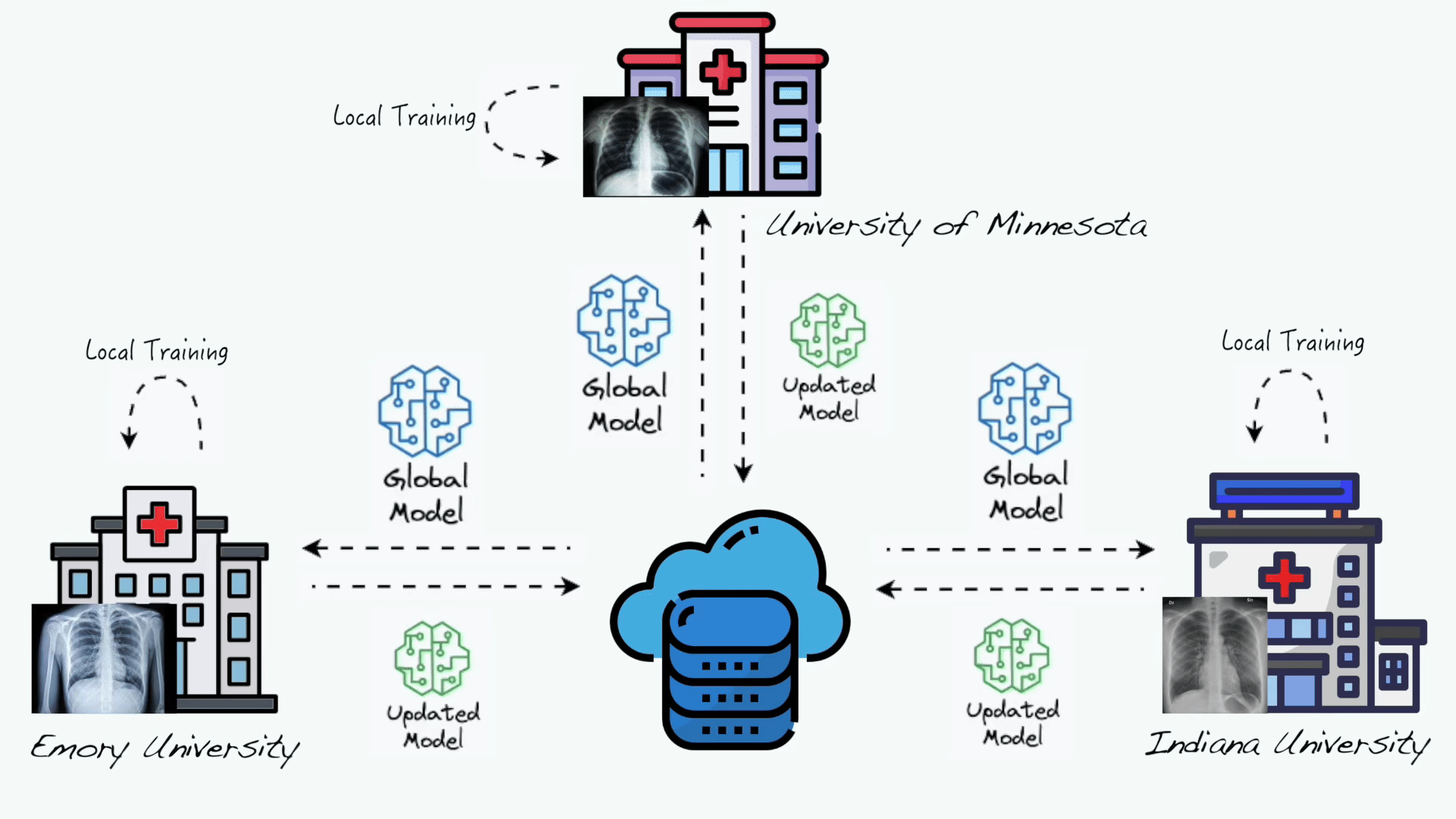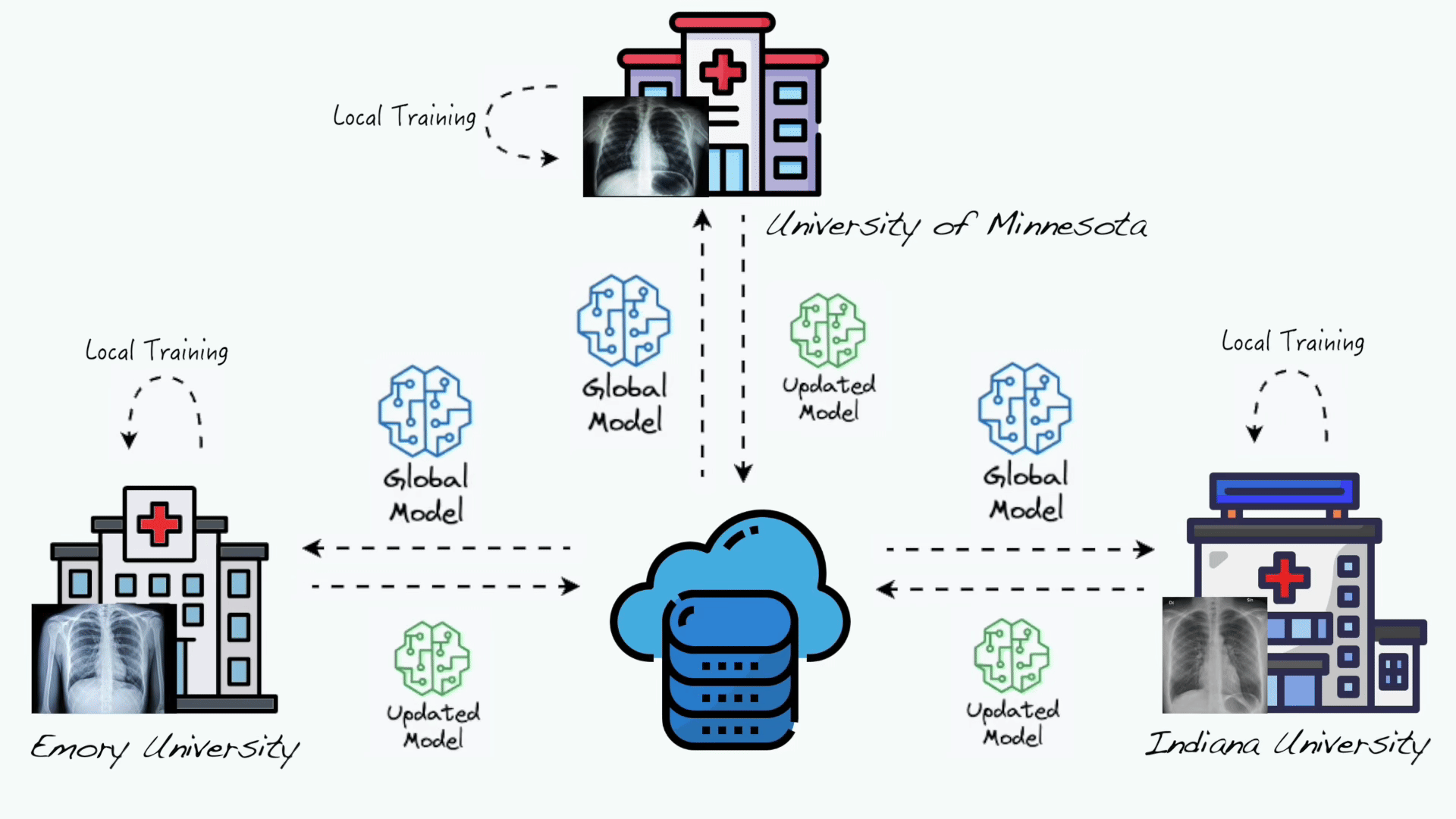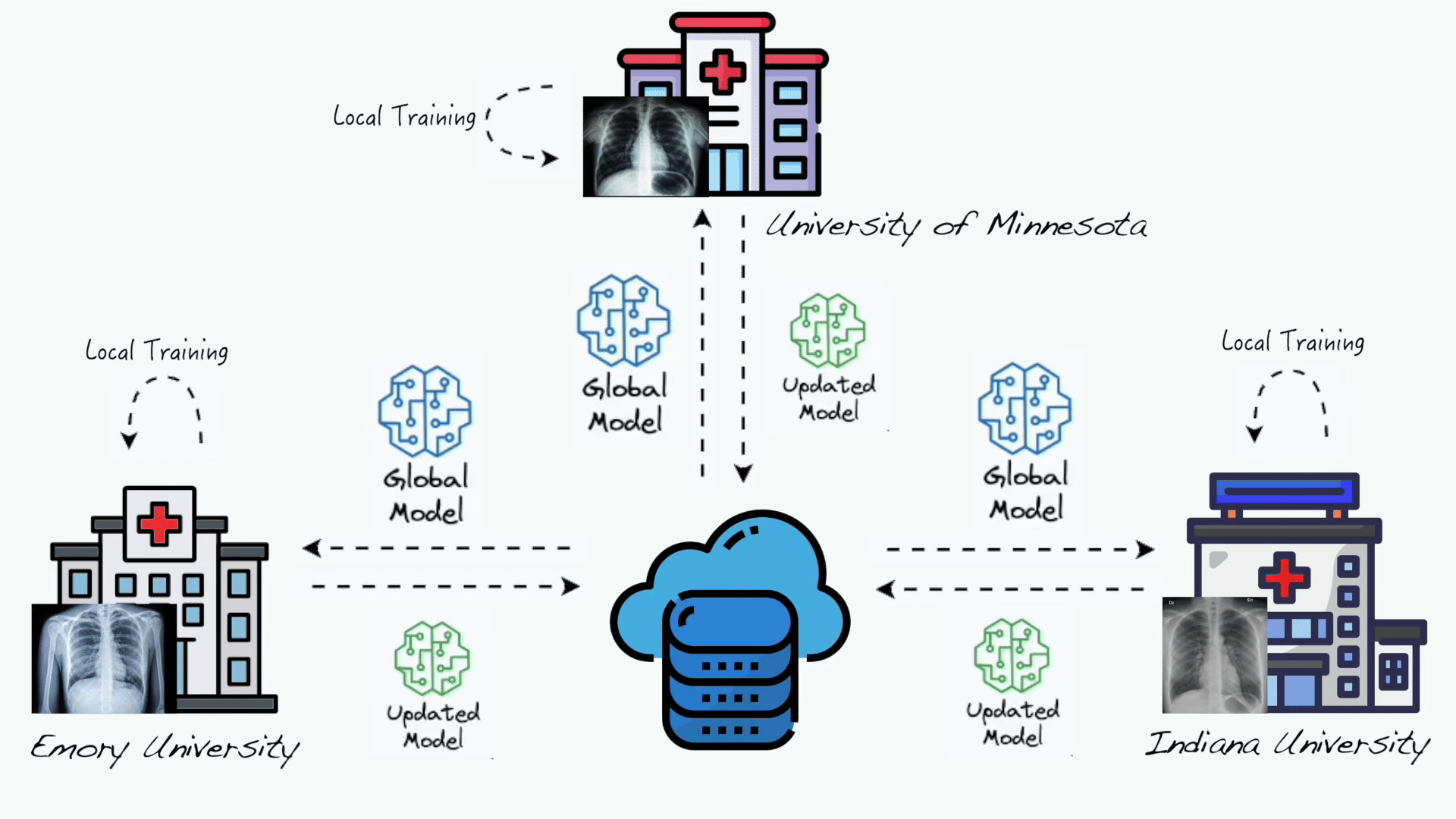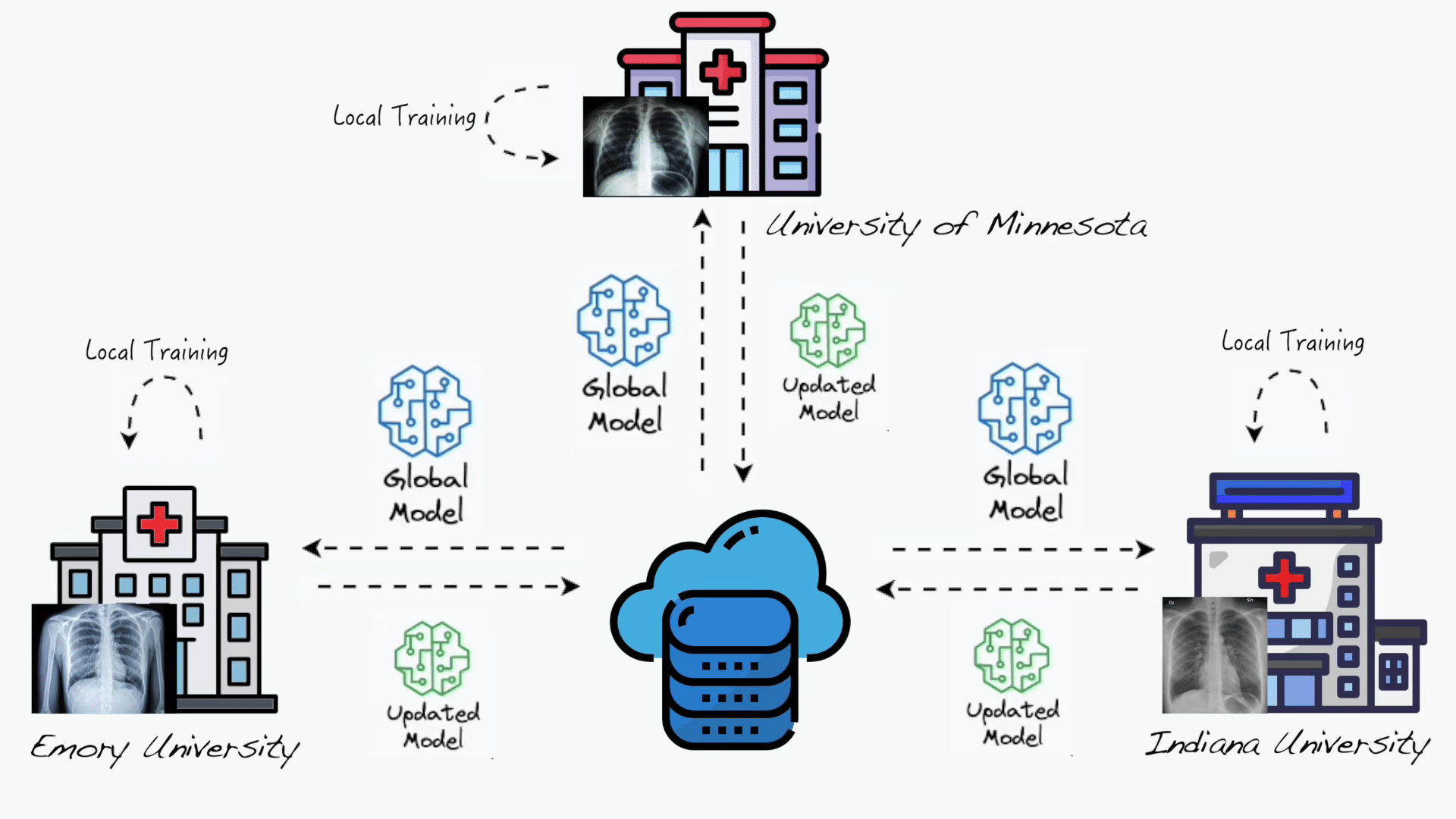 Evaluation of federated learning variations for COVID-19 diagnosis using chest radiographs from 42 US and European hospitalsJournal of the American Medical Informatics Association, Oct 2022
Evaluation of federated learning variations for COVID-19 diagnosis using chest radiographs from 42 US and European hospitalsJournal of the American Medical Informatics Association, Oct 2022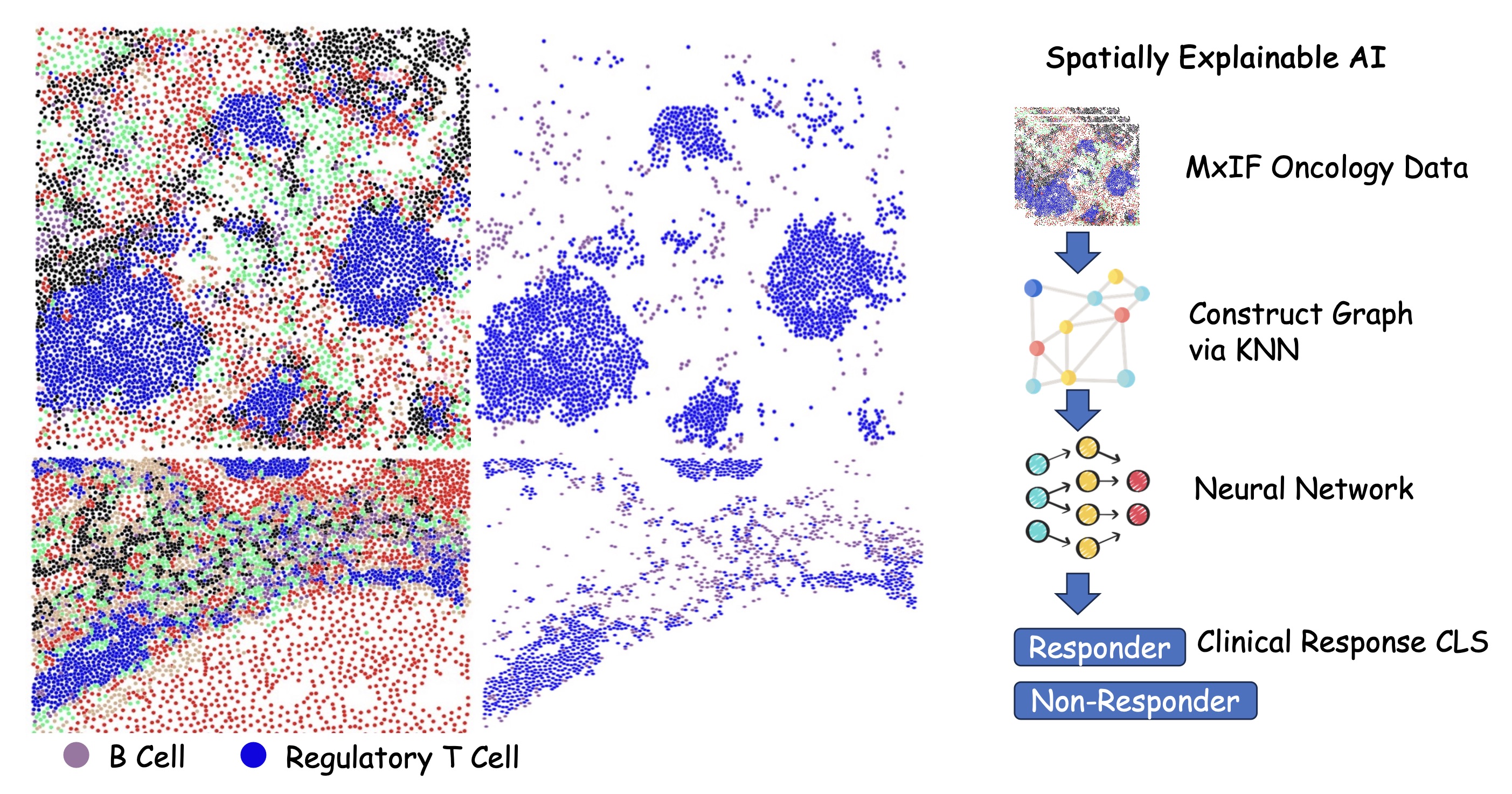 SAMCNet: Towards a Spatially Explainable AI Approach for Classifying MxIF Oncology DataIn Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , Washington DC, USA, Oct 2022
SAMCNet: Towards a Spatially Explainable AI Approach for Classifying MxIF Oncology DataIn Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , Washington DC, USA, Oct 2022